Editorial
White Paper
Why Enterprise AI Fails at Scale

Generative artificial intelligence is transforming publishing, marketing and customer service. By providing personalized responses to user questions, generative AI fosters better customer experiences and makes organizations more productive. A major challenge to using generative AI, however, is ensuring that responses are accurate and brand appropriate.
To understand the potential and challenge of generative AI, consider a customer service scenario where a user contacts a company for information. Traditionally, users would need to scroll through a prewritten set of “Frequently Asked Questions” — a time-consuming task that placed all the burden on the user. To offer a better experience, call centers adopted chatbot technologies that respond directly to user questions. However, chatbots do not perform well when handling complex and nuanced problems. The best solution for users would be to interact with a trained service representative, but this usually requires long wait times.
Large Language Models (LLMs) that enable generative AI can provide a better user experience. LLMs can analyze a user’s question and generate a personalized response. Where LLMs struggle, however, is in providing accurate information. LLMs are trained on large, publicly-available datasets. As a result, an LLM does not know a company’s specific policies or all the unique details of its marketing campaigns or curated content.
An optimal way to improve accuracy is to use an approach called “RAG”, which stands for Retrieval Augmented Generation. RAG enables the LLM to access up-to-date, brand-specific information so that it can generate high-quality responses. In an early research paper, human raters found RAG-based responses to be nearly 43% more accurate than answers created by an LLM that relied on fine-tuning. In this article, we will examine how Retrieval Augmented Generation works and identify key issues you need to consider when using this approach.
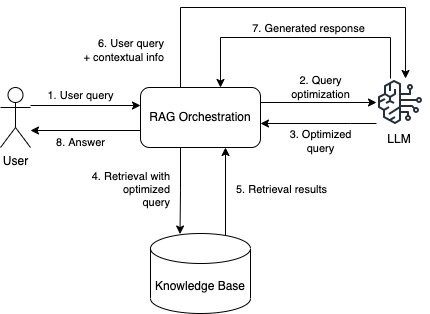
RAG allows you to expand an LLM’s knowledge by using your own content. You construct a knowledge base by indexing your data and linking it to a retrieval system. When a user asks a question, searches in the knowledge base for relevant information that the LLM can use to generate an accurate response.
Figure 1 depicts the general Retrieval Augmented Generation process. When a user submits a search query, the RAG workflow first optimizes the query to retrieve the best information from the knowledge base. Discussing query optimization in depth is outside the scope of this article. At a high level, it refines the original query to align with the user’s search intent and the underlying search technologies. After query optimization and information retrieval, the Retrieval Augmented Generation orchestration layer packages query results with the initial question, then submits everything to the LLM to produce a natural language response for the user.
A few vendors have started offering turnkey RAG solutions and more will undoubtedly enter the market over the next few months. Technology companies also offer components that greatly simplify RAG implementations. Opensource frameworks like LangChain and Hugging Face also provide tools that can orchestrate the RAG approach.
Whether building your own, working with an integrator, or purchasing a solution, you need to be aware of three key issues when implementing RAG:
It should be noted that a number of RAG solutions promise to simplify many of these issues. These new technologies will make RAG more accessible, but you should still be aware of the issues listed above so that you can judge whether a solution truly addresses your needs.
Related Article: Generative AI Technologies: Now and in the Future
Finding the most appropriate information in response to users’ questions depends on understanding their intent. For example, if a user asks “What is a fast chocolate chip cookie recipe?” on a recipe website, search results should show recipes with the lowest preparation time. Requests for “the easiest,” “the cheapest,” and “the healthiest” reflect different intents and would each require different retrieval strategies.
When implementing RAG, you should analyze the types of questions your users will submit. Call center logs, search engine traffic, navigation patterns and user personas can all provide important clues to develop user intent categories. The RAG process will then need to map user questions to the intent categories that you have developed. Traditional text parsing methods tend to be brittle and hard to maintain. A better way to do intent mapping is to use an LLM, since these models excel at understanding textual nuance. During query optimization, you can use prompt engineering strategies to help the LLM determine the appropriate intent category. For a highly specialized domain, such as medical research, you may want to fine-tune the LLM to accurately categorize user intent.
Once the RAG orchestration layer has identified the correct intent, it can retrieve the most relevant information from the knowledge base. If you find that the LLM is not generating good responses to user questions, take a close look at whether your intent categories and information retrieval methods adequately match what your users are looking for.
Related Article: Can Brands Survive Without Leveraging Generative AI?
The quality of the answers produced by RAG depends on the quality of the information you place in your knowledge base. You need to curate your content to find the most accurate and up to date information available. Stale, obsolete, and contradictory information will not result in good answers.
Much of the dialogue on RAG centers on using data that is textual in its original format. However, companies are now producing more video and audio content, which should be represented in your knowledge base. These assets will require special processing to extract metadata and transcripts that you can index in the database.
You should also consider whether you need to extract metadata from your text-based content. For example, to rank recipes for a "fastest preparation" user intent, you need metadata that denotes time. You may need to implement special enrichment processes to create and attach all the metadata needed to support your search use cases. Additional processes may also be required to transform your content before it is placed in your knowledge base. For example, if your content contains sensitive information, such as user names and addresses, you will need processes to remove this data.
The key takeaway is that you need to understand your content and how it will be used before adding it to a knowledge base. You need content that is relevant, focused, in the right format, compliant with privacy and usage guidelines, and enriched with the correct metadata. While many RAG solutions can handle a wide range of information “as is,” higher quality input will lead to higher quality output.
RAG requires thoughtful choices around data access and knowledge base curation to enable relevant retrieval. Depending on where your data comes from, you must optimize it for your target knowledge base. It is important to break longer content into smaller, focused sections by topic before adding it to the knowledge base. Natural divisions like subsections or chapters work well. For very long sources without clear separations, you may need to split the text into chunks using length limits to keep the sections focused. Carefully evaluating how information sources are structured and divided by subject is essential so that the system can efficiently find and retrieve only the parts that are relevant to different question users might ask.
Additionally, RAG knowledge bases can support both lexical search and semantic searches. Lexical searches use keyword search engines that index content based on the exact words in the text. While accurate, this approach does not consider semantic meaning. For instance, "dog bites man" yields the same results as "man bites dog." Semantic searches use vector databases that can discern differences in meaning between text with similar vocabulary, but they do not perform as well as keyword search when looking for a specific name or word.
Many RAG use cases will need knowledge bases that are capable of both forms of search to fully enable retrieval relevance. Take some time upfront to analyze what types of queries your users are likely to ask. That analysis will guide your decisions about what capabilities your knowledge base needs in order to provide helpful answers. The goal is to set up a system that is well-aligned to the ways people will naturally want to access and question your unique data. The analysis will also inform your decision making about how to chunk your different datasets before inclusion in a knowledge base.
Selecting the right search and retrieval mechanisms requires careful analysis that accounts for the types of user queries and the latency of content retrieval. You should be aware that several solutions are now available that can simplify the search and retrieval layer.
Before adopting any generative AI solution, make sure that you have a business problem that the technology can solve. Do you need to answer customer service questions quickly and in a personalized manner? Do you need to provide more intuitive search results? Would your customers benefit from product descriptions and offers generated based on their specific questions? If you are unsure of your use case, you can refer to industry publications for use case guidelines and to stay abreast of the latest technical trends.
Technology companies are starting to offer solutions that will connect LLMs to content sources with little preprocessing and technical development. Although these technologies remove much of the complexity of implementing RAG, you should still take the time to identify your user intent categories and to curate and prepare your content.
Do not assume that the next generation of generative AI solutions will automatically — and magically — create the right responses for your users without any effort on your part. You know your content and users better than anyone. If you combine this expertise with generative AI technologies, you will deliver significant value to your users.
 Learn how you can join our contributor community.
Learn how you can join our contributor community.
Demian is a Senior Partner Solutions Architect for Media & Entertainment at Amazon Web Services, where he helps technology companies develop innovative publishing solutions for content production, data analysis, and monetization. Connect with Demian Hess: 
Aramide Kehinde is a Sr. Partner Solution Architect at AWS focused on Artificial Intelligence and Machine Learning (AIML). Connect with Aramide Kehinde: