News
White Paper
Why Enterprise AI Fails at Scale

Artificial intelligence may already outperform humans in narrow domains, but its path to ubiquity is being slowed by two constraints: high latency and major infrastructure costs.
Taalas claims it has a solution.
The company recently unveiled its first product, a hard-wired implementation of Llama 3.1 8B, delivered as both a chatbot demo and an inference API service. The startup says its silicon version dramatically reduces latency, cost and power consumption compared to conventional AI hardware.
AI’s promise is clear. In many focused applications, models already exceed human performance, and experts predict the technology will lead to a major reduction in workforces by 2030. When used well, AI serves as an amplifier of human productivity and creativity. But two issues currently limit adoption:
Interactions with large language models often lag behind human cognition.
AI has a voracious appetite for resources like energy, water and land. Modern AI deployments require:
Scaling these systems means building sprawling data center campuses and absorbing extreme operational expenses.
Related Article: 13 AI Chip Companies You Should Know About
"Though society seems poised to build a dystopian future defined by data centers and adjacent power plants, history hints at a different direction. Past technological revolutions often started with grotesque prototypes, only to be eclipsed by breakthroughs yielding more practical outcomes."
- Ljubisa Bajic
Co-Founder & CEO, Taalas
Founded roughly 2.5 years ago, Taalas developed a platform that transforms any AI model into custom silicon in about two months after receiving it. The resulting hardware implementations, which the company calls Hardcore Models, are designed specifically for a single neural network.
According to Taalas, compared to traditional software-based inference, these systems are:
Taalas’ approach rests on three core principles:
Rather than building general-purpose AI accelerators, the company creates model-specific silicon. AI inference, it argues, is the most critical computational workload in existence, and the one that benefits most from deep specialization.
Modern AI hardware separates memory (dense, cheap DRAM) and compute (on-chip logic). This divide introduces severe inefficiencies:
| Constraint | Impact |
|---|---|
| Off-chip DRAM access | Thousands of times slower than on-chip memory |
| Memory-compute separation | Requires advanced packaging |
| High-bandwidth memory (HBM) | Increases complexity and cost |
| Massive I/O bandwidth | Drives power consumption |
| Liquid cooling | Adds infrastructure burden |
According to Taalas, it eliminates this boundary by unifying storage and computation on a single chip at DRAM-level density.
By removing the memory-compute divide and tailoring silicon to each model, Taalas redesigned its hardware stack from first principles. Its architecture does not rely on HBM, advanced packaging, 3D stacking, liquid cooling or high-speed I/O fabrics.
This engineering simplicity enables an order-of-magnitude reduction in total system cost, the company claims.

Taalas’ first public product is a hardened version of Llama 3.1 8B. The company selected the model for its small footprint, open-source availability and minimal logistical overhead. And while optimized for speed, the chip retains flexibility through:
Taalas reports the following tokens per second per user:
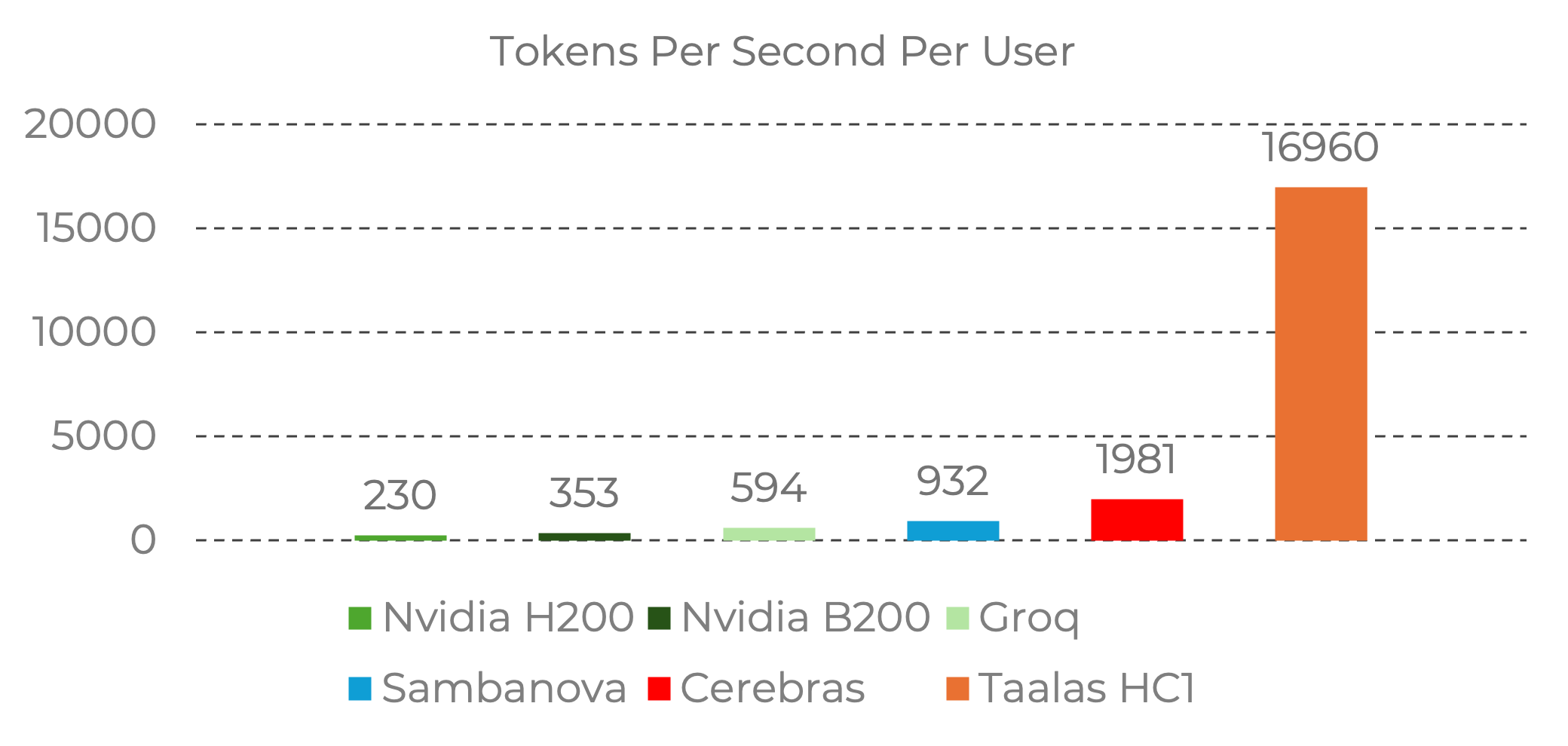
According to the company, its silicon Llama achieves nearly 10X the speed of the current state of the art, while costing 20X less to build and consuming 10X less power.
At the time development began on Taalas's first-generation silicon platform, low-precision formats were not standardized. As a result, some quality degradation exists relative to GPU benchmarks. The company’s second-generation silicon will reportedly adopt standardized 4-bit floating-point formats to address these limitations while maintaining efficiency.
Related Article: The End of Moore’s Law? AI Chipmakers Say It’s Already Happened
Taalas has additional systems planned:
The company plans to release systems early, iterate openly and allow developers to experiment with ultra-low-latency inference.
Developers can now apply for access to the platform to test what can be built when intelligence becomes effectively instantaneous.
Michelle Hawley is an experienced journalist who specializes in reporting on the impact of technology on society. As editorial director at Simpler Media Group, she oversees the day-to-day operations of VKTR, covering the world of enterprise AI and managing a network of contributing writers. She's also the host of CMSWire's CMO Circle and co-host of CMSWire's CX Decoded. With an MFA in creative writing and background in both news and marketing, she offers unique insights on the topics of tech disruption, corporate responsibility, changing AI legislation and more. She currently resides in Pennsylvania with her husband and two dogs. Connect with Michelle Hawley: 
