Feature
White Paper
Why Enterprise AI Fails at Scale

AI supercomputers are advancing at a breakneck pace. New research shows that their performance is doubling every nine months, while hardware costs and energy demands double annually.
These machines now power the largest AI models in existence — some consuming as much electricity as entire cities.
What are the trends shaping AI supercomputers, what do their rising performance and power needs look like and who’s building them?
An AI supercomputer is a large-scale computing system purpose-built to train and run complex artificial intelligence models — especially massive neural networks like GPT-4 or image-generation systems like DALL-E. These machines rely on high-density HPC AI clusters of specialized chips, such as GPUs (graphics processing units) or AI accelerators like TPUs (tensor processing units), working in parallel to handle the billions — or even trillions — of calculations required for AI model training infrastructure.

| Term | Definition |
|---|---|
| AI Supercomputer | A system made up of thousands of specialized chips (often GPUs) used to train large AI models at massive scale. |
| GPU (Graphics Processing Unit) | A high-performance chip optimized for parallel computing tasks central to AI workloads. |
| FLOPs | Floating-point operations per second, the standard unit for measuring AI model training performance. |
| Liquid Cooling | A system that uses chilled liquid, rather than air, to prevent overheating in densely packed AI hardware. |
| Data Center | A facility housing interconnected servers and computing infrastructure, including AI supercomputers like xAI’s Colossus. |
| Megawatt/Gigawatt | Units of electrical power. Large AI supercomputers may consume 100–1,000+ megawatts — comparable to the energy use of a city. |
| Closed-Loop Cooling System | A type of cooling architecture that recirculates coolant fluid, improving energy efficiency and thermal stability. |
| NVIDIA H100 / Blackwell | Leading GPU architectures developed by NVIDIA for AI training. Newer generations demand even more power per chip. |
Unlike traditional supercomputers, which are often used for physics simulations, weather modeling or computational chemistry, AI supercomputers are optimized specifically for matrix math (the core mathematical operation behind most deep learning models) and the types of data processing that modern machine learning (ML) demands. Their strength lies not just in raw compute, but in their ability to move and synchronize data across thousands — or even hundreds of thousands — of chips with minimal delay.
Most AI supercomputers implement a data center-scale architecture (a computing system design where the entire data center functions as one massive, unified computer — rather than just a collection of independent servers), often built using GPU clusters connected by ultra-high-speed networking (like NVIDIA’s NVLink or custom interconnects).
These systems are usually housed in hyper-scale facilities (massive data centers built to support extremely high volumes of compute, storage and networking) and rely on advanced AI data center cooling solutions, robust power distribution and software orchestration to function at peak efficiency.
Related Article: Supercomputing for AI: A Look at Today’s Most Powerful Systems
AI supercomputers aren’t just getting stronger — they’re advancing at a pace that rivals and in some cases outpaces Moore’s Law (the premise that the number of transistors on a computer chip tends to double about every two years).
A recent arXiv study analyzed a dataset of over 500 systems from 2019 to 2025 and found that the median computational performance of leading AI supercomputers, driven by exascale computing for AI innovations, has doubled roughly every nine months — a compound growth rate of about 2.5x per year.
That growth is measured in floating point operations per second (FLOPs), the key metric for AI workloads. FLOPS measure how fast a computer can perform math — specifically, the kind of calculations used in AI and scientific computing. The higher the FLOPs, the more math a system can do each second, and the faster it can train or run complex models.
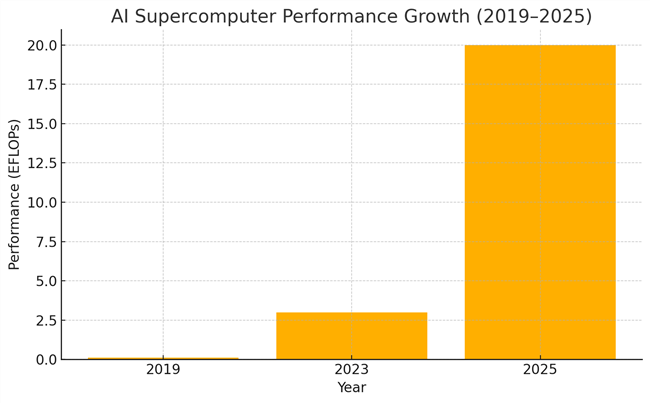
In practical terms, this means the amount of compute available to train cutting-edge models has increased by an order of magnitude in just a few years. In 2019, a high-end system might have offered around 100 petaFLOPs (one petaFLOP refers to one quadrillion [1,000,000,000,000,000] floating point operations per second).
| Category | 2019 | 2023 | 2025 (Projected) |
|---|---|---|---|
| Performance (FLOPs) | ~100 PFLOPs | 1-5 EFLOPs | 20+ EFLOPs |
| Median Cost | $100-$200M | $500-$800M | ~$1B+ |
| Power Usage | ~10-20 MW | 50-150 MW | 300+ MW |
By 2023, top-tier builds — like Meta’s Research SuperCluster — crossed the 1 exaFLOP (one quintillion floating point operations per second) threshold. Now, in 2025, we’re seeing performance levels reaching 20 exaFLOPs and beyond, with the most ambitious systems scaling toward even higher capacities.
| Unit | Operations Per Second |
|---|---|
| GigaFLOP | 1 billion (1,000,000,000) |
| TeraFLOP | 1 trillion (1,000,000,000,000) |
| PetaFLOP | 1 quadrillion (1,000,000,000,000,000) |
| ExaFLOP | 1 quintillion (1,000,000,000,000,000,000) |
ExaFLOP Explained: An exaFLOP equals one quintillion floating point operations per second. That’s a billion billion calculations every second—enabling the training of the largest AI models in existence.
To put it in perspective: If a human did one calculation per second, it would take over 31 billion years to match what an exaFLOP system does in one second.
xAI’s Colossus harnesses 20,000 NVIDIA H100 clusters (a model of exascale computing for AI) and is engineered to train some of the largest AI models in existence.
Or Frontier, housed at Oak Ridge National Laboratory, which became the world’s first publicly known exascale system (a supercomputer capable of performing at least one exaFLOP, or one quintillion [10¹8] floating point operations per second — that’s a billion billion calculations every second) and remains one of the fastest for a wide range of scientific and AI workloads.

Lei Gao, chief technical officer at SleekFlow, said he believes the AI infrastructure model is evolving. "Instead of a single monolithic supercomputer, we’ll see interconnected systems across edge, cloud and on-prem environments working in concert. The rise of modular models and retrieval-augmented architectures will reduce dependence on massive end-to-end training runs." Gao envisions a future in which modular, latency-aware AI systems offer resilience and context-specific performance without the need for colossal, centralized infrastructure.
As of now, however, large-scale AI models continue to push the limits of what supercomputers can handle. These systems don’t just enable faster training — they unlock entirely new dimensions of model scale, from trillions of parameters to emergent multi-modal capabilities. But this performance explosion comes at a cost, namely, skyrocketing power requirements and growing financial strain.
Related Article: The End of Moore’s Law? AI Chipmakers Say It’s Already Happened
"A huge challenge in scaling the cost-efficient performance of large systems will be handling the massive power delivery and cooling requirements."
- Mike Frank
Senior Scientist, Vaire Computing
The rapid rise in AI supercomputing performance comes with a steep energy bill. Power consumption for large-scale AI systems has doubled roughly every 12 months, according to a Forbes report, outpacing gains in energy-efficient AI hardware and placing unprecedented strain on data-center infrastructure and local power grids.
Some of the largest AI supercomputers now consume energy on the scale of small cities. xAI’s Colossus, for example, is estimated to draw up to 300 megawatts — enough to power over 250,000 US homes. Even more conservatively sized systems can demand tens of megawatts, placing unprecedented strain on data center infrastructure and local power grids.
The industry is increasingly recognizing that energy use isn't a side effect — it's a defining constraint. Many experts believe we're nearing a critical threshold. Danilo Coviello, industry trends researcher and digital marketing specialist at Espresso Translations, explained, "We are talking the amount of energy use that could match whole cities... intensive cooling, mostly based on liquid or immersion systems, is gradually taking the place of archaic air cooling. This is no longer mere added options; they are necessities."
As AI supercomputers continue to scale, thermal output and power delivery have become critical bottlenecks. "A huge challenge in scaling the cost-efficient performance of large systems will be handling the massive power delivery and cooling requirements," said Mike Frank, senior scientist at Vaire Computing. "However, advanced cooling solutions do nothing to address the raw cost of the energy needed to power future HPC AI systems."
This growth is raising serious questions about AI sustainability. While traditional supercomputers often serve shared academic or government purposes, AI supercomputers are increasingly deployed by private companies training proprietary models — leading to concerns about carbon footprints, energy equity and resource allocation.
As demand for AI infrastructure accelerates, many industry leaders are doubling down on renewable and nuclear energy as the primary paths toward sustainability. But Frank cautions that this focus may overlook a deeper issue: the environmental cost of industrial expansion itself. “In our opinion, industrial expansion alone cannot satisfy future demand for AI — it's critical to also find new ways to increase the raw energy efficiency of computing technology." In other words, shifting to cleaner energy isn’t enough. True sustainability will depend on developing fundamentally more efficient hardware that consumes less power to begin with.
Cooling and power aren’t abstract issues — they’re among the most cited physical bottlenecks in scaling AI supercomputers. According to Tony Tong, chief technical officer at Intellectia.AI, "Builders are tackling this by using smarter cooling solutions, like liquid cooling, and designing special hardware chips optimized just for AI workloads."
Some builders are responding with innovations in cooling (like liquid immersion), custom chip architectures with improved efficiency and partnerships with renewable energy providers. But the bottom line remains: the race for AI scale is also a race for power — literally. And the faster performance grows, the more urgent the sustainability challenge becomes.
As AI supercomputers scale in complexity and capability, they’re also becoming vastly more expensive.
The median cost of building a high-end AI system is now approaching $1 billion, with elite builds like xAI’s Colossus and OpenAI’s Azure-powered infrastructure estimated to exceed that mark. These aren't just IT projects — they're infrastructure investments on par with national research facilities or energy plants.
What stands out is not just the price tag, but who’s footing the bill. Over the past five years, there’s been a sharp shift in ownership from government labs and academic institutions to private tech giants. Businesses like OpenAI (via Microsoft), Meta, Google DeepMind and xAI now operate the world’s most powerful AI systems, often in partnership with hyperscale cloud providers like AWS, Azure and Google Cloud.
As compute resources concentrate in the hands of major tech companies, smaller teams often face steep barriers. "For small teams or startups, access is no longer a function of ability — it’s access to affordable, scalable compute," said Gao. "This is why open-source model ecosystems and cloud-native AI services are so important."
While private ownership has accelerated infrastructure development, Gao noted, it risks deepening divides in who can realistically participate in advanced AI development.
This trend has decreased the share of publicly funded builds, particularly in the US, where commercial investment now dominates the space when it comes to AI infrastructure. While national labs like Oak Ridge and Argonne still play a role, much of the cutting-edge capacity for training LLMs has moved into the hands of a few well-capitalized firms.

Related Article: 10 Top AI Chip Companies
| Entity Type / Region | Estimated Share of Compute | Notable Examples |
|---|---|---|
| United States (Private Sector) | ~75% | OpenAI/Microsoft, Meta, xAI, Google |
| China (Public + Private) | ~15% | Baidu, Huawei, Tsinghua University |
| Rest of World | ~10% | EU HPC centers, Middle East initiatives |
As the cost curve steepens, the ability to build and operate these systems is becoming a strategic advantage—one that’s reshaping not just the AI industry, but the geopolitical dynamics of innovation itself.
The race to build AI supercomputers isn’t just a tech story — it’s a geopolitical one. As of 2024, roughly 75% of the world’s large-scale AI compute capacity resides in the United States, with China holding around 15% and the remainder spread thinly across the EU, UK, Middle East and a handful of other regions. This concentration of compute power has profound implications for both national security and the global competition for AI dominance.
AI systems are increasingly seen as strategic infrastructure — similar to nuclear reactors or semiconductor fabs. That’s led to rising tensions around chip exports, with US restrictions aimed at limiting China’s access to advanced AI hardware like NVIDIA’s H100s. In response, China is investing heavily in domestic chip manufacturing and model development, while other nations are racing to catch up with sovereign AI initiatives and public-private partnerships.
But it’s not just countries — it’s companies. A small handful of US-based tech giants now control most of the usable frontier compute (the most powerful, cutting-edge computational systems available at any given time). This centralization of AI infrastructure raises questions about global access, innovation equity and who gets to shape the future of AI.
In the coming years, we’re likely to see compute become not just a technical resource, but a lever of international influence, economic policy and regulatory tension.
Scott Clark is a seasoned journalist based in Columbus, Ohio, who has made a name for himself covering the ever-evolving landscape of customer experience, marketing and technology. He has over 20 years of experience covering Information Technology and 27 years as a web developer. His coverage ranges across customer experience, AI, social media marketing, voice of customer, diversity & inclusion and more. Scott is a strong advocate for customer experience and corporate responsibility, bringing together statistics, facts, and insights from leading thought leaders to provide informative and thought-provoking articles. Connect with Scott Clark: 