Feature
White Paper
Why Enterprise AI Fails at Scale

When frontier AI models began achieving top scores on academic benchmarks, researchers faced a problem: those tests stopped revealing meaningful information.
Humanity’s Last Exam was created to address that challenge. It measures where advanced AI still falls short, why older evaluations are less useful and how AI assessment should evolve.
AI benchmarking has been key for measuring progress, comparing how well individual models perform on academic tests:
As models improve, however, these benchmarks become less revealing. When top systems cluster near the highest possible scores, the results no longer distinguish shallow pattern recognition from deeper reasoning. This saturation poses problems as AI enters real-world use. Businesses, policymakers and researchers rely on benchmarks to understand AI capabilities. When tests no longer measure meaningful differences, there's a risk of overstating AI progress.
Related Article: The Benchmark Trap: Why AI’s Favorite Metrics Might Be Misleading Us
One reason behind this new challenge is the original design of many benchmarks. Tests like MMLU use questions designed for human learners, often from undergraduate exams. LLMs, trained on vast internet text, excel at spotting statistical patterns, making these questions easier to answer without deep understanding.
The widespread availability of benchmark questions online further complicates evaluation, since LLM training data likely includes them. As Betsy Hilliard, chief science officer at Valkyrie Intelligence, put it: "The questions and answers are everywhere on the internet. Which means the LLMs have ingested the answer key multiple times over."
High scores on traditional benchmarks can therefore give a misleading impression of deeper reasoning or expertise. Models may be recognizing familiar question patterns rather than demonstrating true understanding.
Humanity’s Last Exam is a new benchmark designed to test the limits of advanced AI systems. Developed by a global consortium — led by the Center for AI Safety — and published in Nature in January 2026, it includes roughly 2,500 questions contributed by nearly 1,000 experts from over 500 institutions in about 50 countries. Organizers offered prizes up to $5,000 for top questions.
This AI benchmark covers over 100 subjects spanning major academic domains, including:
| Domain | Examples of Topics |
|---|---|
| Mathematics | Advanced proofs, theoretical computer science, algorithmic reasoning |
| Natural Sciences | Biology, chemistry, physics, specialized scientific subfields |
| Humanities | History, philosophy, cultural analysis |
| Ancient Languages | Palmyrene inscriptions, Biblical Hebrew phonology |
| Specialized Academic Fields | Microanatomy, rare research domains, expert-level scholarly topics |
Unlike traditional AI evaluations relying on standardized academic or publicly available questions, Humanity’s Last Exam aims to remain difficult for frontier models, focusing on expert-level questions where modern systems still struggle.
Questions were written and reviewed to have single, verifiable answers and demand more than pattern recognition. About 25% are multiple-choice; most require exact answers. Some require multimodal reasoning, interpreting text and visuals together.

The test is a research tool, not a human student exam. Questions answerable by leading models were removed, leaving a benchmark intentionally just beyond current AI capabilities to identify remaining gaps from expert knowledge.
Early results from Humanity's Last Exam show even advanced AI models perform poorly on many questions.
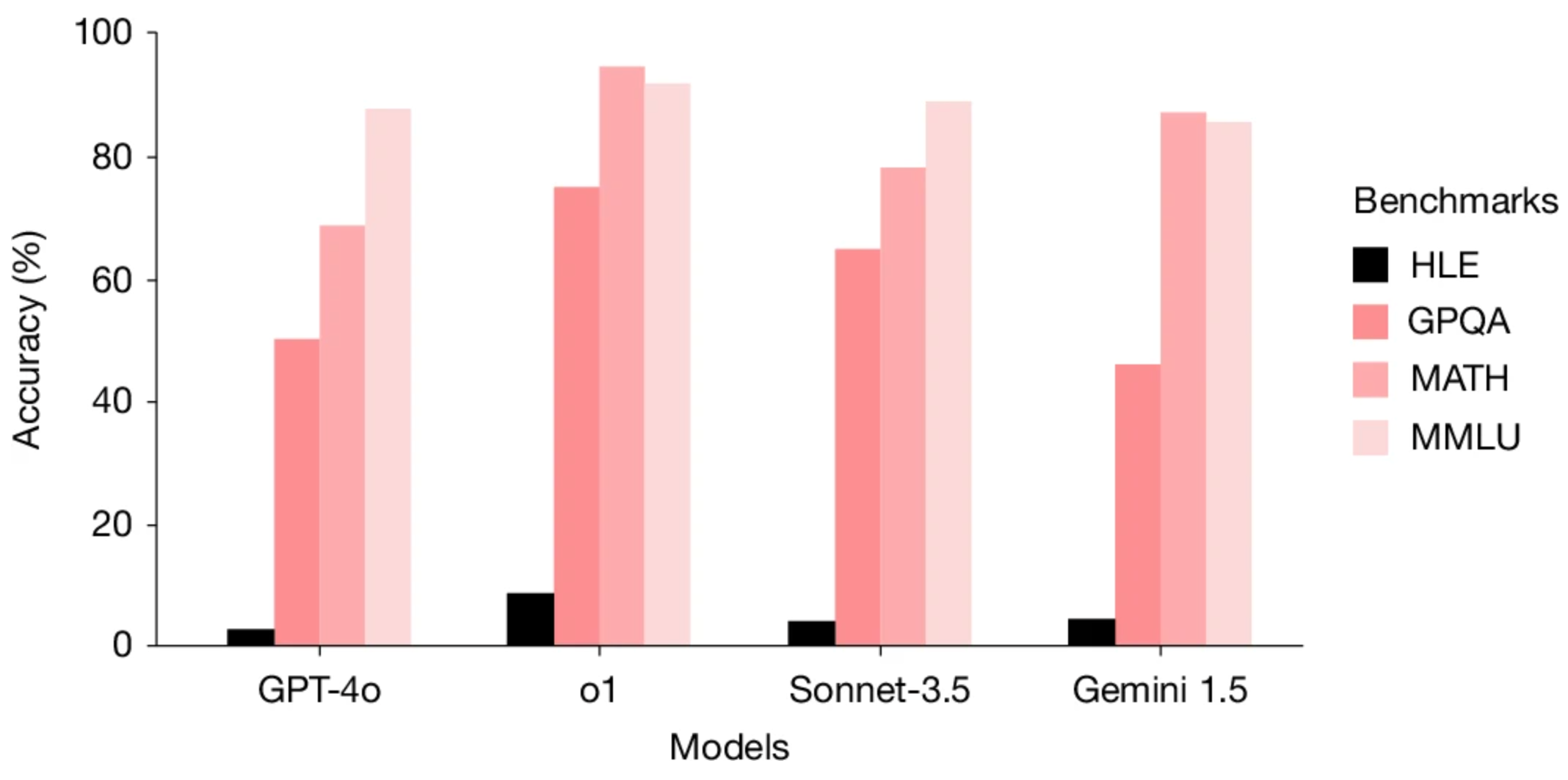
While early evaluations showed very low accuracy, more recent frontier models improved into the 40% range — but many questions remain unanswered.
| AI Model | Developer | Approximate Accuracy |
|---|---|---|
| Gemini 3.1 Pro Preview | 44.7% | |
| GPT-5.4 | OpenAI | 41.6% |
| GPT-5.3 Codex | OpenAI | 39.9% |
| Gemini 3 Pro Preview | 37.2% | |
| Claude Opus 4.6 | Anthropic | 36.7% |
"The initial findings indicate that AI systems are much worse in their ability when compared to their classic benchmark scores," said Jitesh Keswani, CEO at e intelligence. "A model with a score of 90 percent on MMLU could have a score of 40 percent on HLE and that difference is the real account."
Related Article: AI Isn't Actually Intelligent: Why We Need a Reality Check
Benchmarks tend to lose distinction as they become widely known and models are optimized to perform well. This pattern has repeated across AI evaluations, reducing their usefulness over time.
The creators of Humanity’s Last Exam addressed this by limiting public availability of most questions. Some portions are released for transparency and research, but most remain hidden to reduce risk of models memorizing answers or tuning specifically for the test. A key lesson of HLE is that benchmark design cannot be static.
Despite the test creators' cautionary measures, the long-term usefulness of any benchmark is uncertain. Frontier models improve rapidly and may eventually perform much better on HLE, prompting the need for new evaluations.
Many researchers view benchmarks as iterative tools requiring updates as AI progresses. Humanity’s Last Exam may remain useful if it continues to challenge advanced systems, but its main contribution may be demonstrating the need for evolving benchmarks.
Scott Clark is a seasoned journalist based in Columbus, Ohio, who has made a name for himself covering the ever-evolving landscape of customer experience, marketing and technology. He has over 20 years of experience covering Information Technology and 27 years as a web developer. His coverage ranges across customer experience, AI, social media marketing, voice of customer, diversity & inclusion and more. Scott is a strong advocate for customer experience and corporate responsibility, bringing together statistics, facts, and insights from leading thought leaders to provide informative and thought-provoking articles. Connect with Scott Clark: 