Editorial
White Paper
Why Enterprise AI Fails at Scale

Editor's note: Patrick Hoeffel — managing partner at Patrick Hoeffel Partners — and Sanjay Mehta — an advisor at Earley Information Science — contributed to this article.
In recent years, the landscape of search technology has been progressively revolutionized by the advent of generative AI. The latest advance in that progression is OpenAI’s SearchGPT — an attempt by OpenAI to retrofit its market-leading generative AI capabilities onto the traditional search landscape. This evolution transcends the traditional indexing of content and taps into an intricate understanding of user intent, leveraging the probabilistic nature of language models to deliver more personalized and accurate results.
All of the major search vendors are integrating large language models (LLMs) into their search experiences. For web-based search, the possibilities are confusing and inconsistent.
The following illustrates three different ways that content is indexed and used in search experiences, both with and without LLMs.
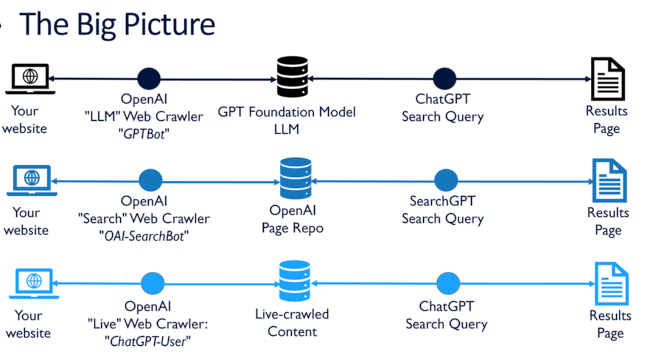
In the example of OpenAI, different crawlers are used to gather data from the web.
What’s important about these mechanisms is the data freshness that each provides. In the case of OpenAI’s foundation models, the crawled data is usually at least nine months old at a minimum at the time the models first launch. In the case of data crawled for SearchGPT, the data is much more fresh, like Google’s data, typically being not more than a few days old and in some cases, only hours or minutes old. In the case of OpenAI’s “ChatGPT-User” bot that runs inside ChatGPT, the data is current as of the moment the question is answered. This difference is significant and is important to bear in mind when choosing the search method that will best suit the needs of your use case.
In a recent webinar on the topic, Jeff Coyle of Marketmuse illustrated the various experiences that this can render through either OpenAI search experiences or those through Google or Bing.
In Google, LLM queries are called “AI Overviews” (AIO) and are presented at the top of a search results page that also includes more familiar search elements. These include a knowledge panel (which leverages explicit metadata using schema.org structured data standards), organic search results, a “People Also Asked” (PAA) component and a “People Also Searched For” (PASF) component.
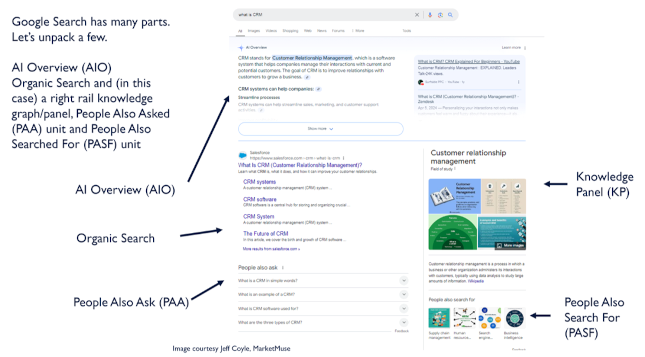
In some cases, citations are included, and each of these components can be further expanded or broken down.
Traditional search engines typically rely on both structured metadata and unstructured derived metadata with a series of ranking algorithms used to determine the relevance of search results. Today, the integration of ontology-driven vectors in search technologies is pivotal. Ontologies serve as a backbone, providing structured paths based on user roles and contexts, which significantly enhance information retrieval efficiency.
Ontologies can be used to define user entry vectors, ensuring the retrieval of information aligns seamlessly with the user's specific role within an enterprise. This strategy is akin to enterprise content management (ECM) systems but enriched with AI's evolving capabilities.
A good example of this is auto parts search. The auto parts domain ontology describes each of the different car parts that can be purchased from either a manufacturer or an aftermarket auto parts store. Each type of part has a location in a giant parts tree (the ontology), such that brake pads are part of the braking system, which is part of the wheel system, which is part of both the drivetrain and steering systems. A brake pad has a set of properties that describe it, and every company that makes and sells brake pads uses the properties defined in the car parts ontology under brakes pads to describe their brake pads. This allows a search engine when facing a query for “ceramic” to know the user could definitely be talking about brake pads but is definitely not talking about steering wheels or spare tires.
Most data sets don’t come with a predefined ontology, unfortunately. If they did, search results, especially internal searches inside large companies, would be much, much more effective.
One of the most profound implications of generative AI for traditional search engines is the emergence of retrieval-augmented generation (RAG). By embedding explicit metadata into the retrieval process, RAG enriches content, making it more accessible and relevant to specific search queries. This approach ensures the information presented is not only accurate, but contextually useful.
For instance, in enterprise settings, understanding user roles can dramatically improve content relevance. Whether it's a sales executive seeking the latest marketing collateral or a product engineer looking for updated specifications, personalized content delivery is key. A hybrid approach uses predefined user roles within closed systems to allow for quicker and more precise information retrieval.
As search engines evolve, so does the emphasis on producing authoritative, valuable and trustworthy content. In the world of SEO and digital marketing, creating content that resonates with both AI algorithms and human readers is crucial. High-quality content structured with schemas appropriate to the use cases the content supports not only improves visibility in search engines like Google, but also aligns with the mechanisms of LLMs, enabling more nuanced and accurate content generation by incorporating additional signals the model can leverage.
LLM memory capabilities retain user interactions to deliver progressively more refined responses. Through detailed custom instructions, AI can tailor responses based on past interactions, significantly enhancing the personalization of content delivery. For example, continuous queries about a specific topic will progressively yield more accurate and focused results.
This capability is very different from typical search engines where every query is stateless and has no awareness of the searches that were submitted before, even when they come from the same user in the same session. In this respect, GenAI has made the search world a much friendlier place.
Looking ahead, the rise of expert models tailored to specific industries — such as life sciences, financial services and insurance, industrial manufacturing and distribution — as well as business functions and tasks (SEO, sales, marketing communications and employee onboarding, for example) will continue to evolve, making LLM-powered applications more capable. It is important to make the distinction between the knowledge models we are referring to and the LLMs the algorithm runs on. These knowledge models are driven by, and are part and parcel of, knowledge graphs. This is because a knowledge graph links the information scaffolding of the ontology (comprised of taxonomies and the relationship between them — services for solutions, for example) to the organization’s operational data. This powerful combination delivers more informed and accurate content, setting new standards for information retrieval. Imagine a Salesforce-specific model that personalizes outputs based on deep industry expertise, fundamentally transforming how businesses access and utilize information.
Traditional search engines such as Google have started implementing generative answers alongside conventional search results. This dual approach, integrating generative models with traditional keyword-based searches, ensures a more comprehensive and relevant user experience.
LLM-powered generative search alters the dynamics of user interaction. Unlike traditional search prompts, which are often short and specific, generative search thrives on more expressive, sentence-like inputs. This shift necessitates a familiarity with crafting detailed prompts to fully leverage the AI’s capabilities.
One of the core tenets of software usability is the principle of expectation management. When a user has an expectation of a certain result from a system and that expectation is satisfied, then the user’s goal is achieved, and the user’s experience is positive. When the user brings a certain expectation to an experience and the result is other than what the user expects, then the experience is negative. It doesn’t matter if the user’s expectation to begin with was reasonable or not — it only matters whether or not the system met that expectation.
If I use Google and ask, “Who won the 2020 world series,” I know it’s October, and I’m thinking about Major League Baseball in the United States, but Google doesn’t know that. Nonetheless, Google satisfies my expectation and returns “Los Angeles Dodgers” in giant print across the top of the page. I might have been thinking about the World Series of Poker, or the College World Series or even the Little League World Series. Page 3 of Google’s results lists the World Series of Team Calf Roping — interesting, I guess, but definitely not aligned to my expectation.
Generative search is changing our collective minds about what we can expect as results from a search engine. I asked ChatGPT the other day what the HTML code is for italics. I expected a one-line answer: “<i>”. What I got instead was three pages of the several different ways that effect could be achieved, along with an analysis of the pros and cons of each, including examples of how to use each method. Okay, but I didn’t need that, and I didn’t want to wait 30 seconds while it generated.
My expectations were changed by this experience, and I will now be more judicious about which tool I use for which task. My understanding of what is possible has also changed and with it, so has my expectation for what I can get in my “search” results. As the result content changes underneath me, so too does my expectation of what I will get. As a result, what may have been a very satisfying result from Google or Bing yesterday is likely disappointing today.
To maximize the benefits of generative AI in search engines, follow these guidelines:
The integration of generative AI into search engines marks a significant milestone in the evolution of information retrieval. By combining ontologies, metadata and advanced language models, platforms such as OpenAI’s SearchGPT are pushing the boundaries of what’s possible in content accessibility and personalization. As we move forward, embracing these technologies will be essential for enterprises looking to stay ahead in a rapidly changing digital landscape.
The next phase of this transformation will involve more sophisticated expert knowledge models and a deepened focus on high-quality, authoritative content — a journey that promises to redefine the way we interact with and derive value from information.
 Learn how you can join our contributor community.
Learn how you can join our contributor community.
Seth Earley is the founder and CEO of Earley Information Science, a professional services firm working with leading brands. He has been working in the information management space for over 25 years. His firm solves problems for global organizations with a data/information/knowledge architecture-first approach. Earley is also the author "The AI-Powered Enterprise," which outlines the knowledge and information architecture groundwork needed for enterprise-grade generative AI. Connect with Seth Earley: 