Editorial
White Paper
Why Enterprise AI Fails at Scale

The AI revolution has not emerged from a single breakthrough — it’s the result of many foundational technologies. While analytical AI, generative AI and agentic AI may serve different functions, they share a deep reliance on data infrastructure, cloud computing and deep learning models. Generative and agentic AI go further, built on the transformative power of large language models (LLMs), vector databases and transformer architectures. Agentic AI adds the critical ingredients of workflows and scripting to drive autonomy.
In this fifth installment of the AI Revolution series, I’ll explore each of these technologies and how they fuel different AI approaches — and what makes each distinct.
Before proceeding, I would like to thank Professor Kevin Elder, the Gary A. Moore Family Endowed Professor of Analytics & Cyber Security at Louisiana Tech University College of Business, for his thoughtful review and insightful comments in this article.
Editor's Note: Want to learn more? Check out Part 1, Part 2, Part 3 and Part 4 of our AI Revolution series.
Industrializing data is the foundational step in making all organizations AI-ready — and yet, it remains elusive for most. At its core, industrialization involves making data broadly available across the entire enterprise. This starts with moving data through modern data pipelines or, increasingly, by enabling virtualized access that eliminates the need for physical replication. Without this foundational access, no AI model — no matter how sophisticated — can deliver business value.
But access is only the beginning. Data must also be transformed — cleansed, corrected and standardized — to ensure it meets critical thresholds for accuracy, timeliness, consistency, completeness, coherence, interpretability and security. This process isn't just technical; it's deeply organizational. It requires aligning business domains around a single source of truth to eliminate redundant definitions, conflicting metrics and data chaos.
As Marco Iansiti and Karim Lakhani write in "Competing in the Age of AI," “this process gathers, inputs, cleans, integrates, processes and safeguards data in a systematic, sustainable and scalable way.” Clearly, all this is done through dataOps and governance processes. The payoff for succeeding here is significant. According to Dresner’s 2025 Research, the organizations that are most successful with their BI initiatives are most likely to have already deployed generative AI — over 80% of the top performers already have. Not coincidentally, these organizations report the highest BI penetration.
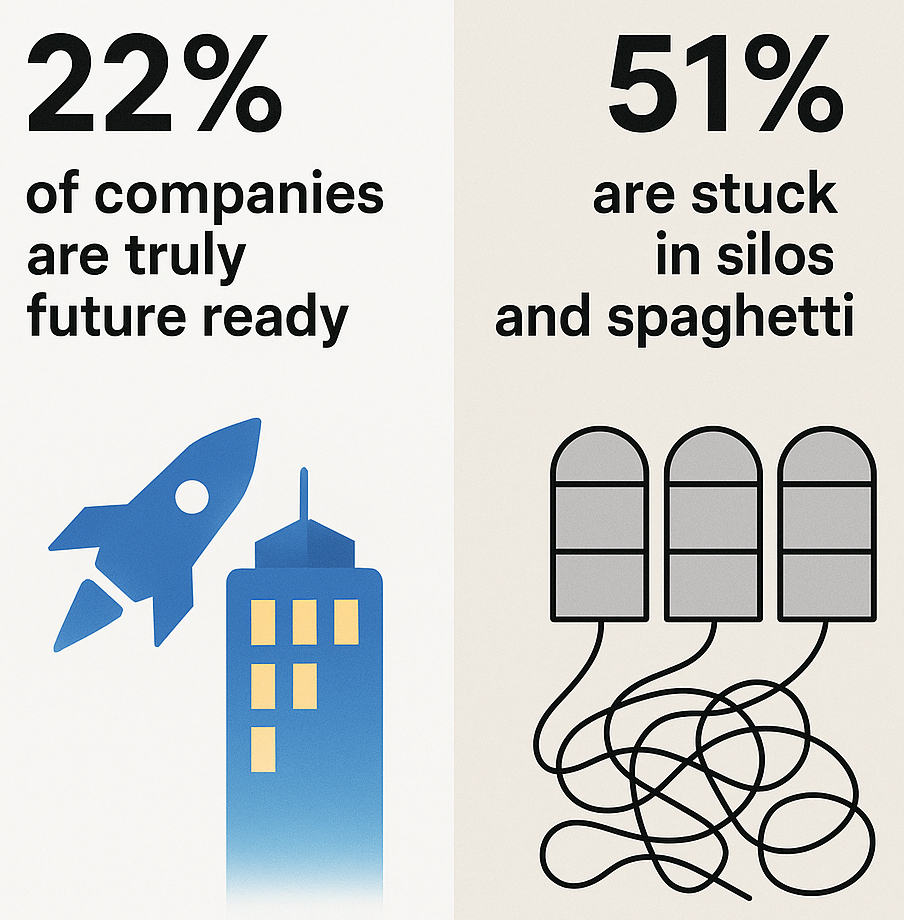
And yet, the reality for many firms is far less advanced. MIT-CISR research shows that only 22% of companies are truly “future ready” — meaning they’ve both industrialized their data and overhauled the customer experience. Meanwhile, a staggering 51% remain stuck in a state of “silos and spaghetti” — riddled with disconnected point solutions, redundant systems and incompatible technologies.
The message is clear: AI success depends on industrialized data. Those who treat data readiness as a core business capability will lead. The rest will struggle to scale beyond pilot projects.
Related Article: Is Your Data Good Enough to Power AI Agents?
“Delivering on the promise of AI — whether agentic, generative or operational — requires robust data, infrastructure and governance polices. That’s why we see more organizations turn to hybrid cloud strategies, which offer the flexibility and control to run AI workloads where they perform best..."
- Nirmal Ranganathan
CTO Public Cloud, Rackspace
To make AI work well, companies are simplifying how their technology is set up. Instead of using lots of separate tools, they’re combining them and moving to cloud-based systems. This makes it faster and easier to get AI up and running — and to grow it. This radically simplified architecture is key to AI success. By streamlining the tech stack into cloud-native platforms, organizations can accelerate implementation timelines and reduce complexity. This simplification isn’t just about efficiency; it’s about achieving AI at scale.
Managing fewer, more integrated data systems allows data teams to focus on what matters: growing AI capabilities, not babysitting infrastructure. The result is a massive productivity boost. Teams spend less time wrangling storage or maintaining systems and more time building value — through analytics, modeling and automation.
According to Nirmal Ranganathan, CTO Public Cloud for Rackspace, “Delivering on the promise of AI — whether agentic, generative or operational — requires robust data, infrastructure and governance polices. That’s why we see more organizations turn to hybrid cloud strategies, which offer the flexibility and control to run AI workloads where they perform best, whether in an on-premises data center or through a large-scale public-cloud provider. This workload-aware approach empowers organizations to innovate faster, operate securely and scale with confidence.”
According to the 2025 research, its most valued attributes include:
These qualities reduce administrative burdens and enable faster experimentation and deployment — both essential for maturing AI initiatives. There’s also a strong link between cloud BI adoption and overall BI success. Among organizations that report being completely successful with BI, 68% say cloud BI was very important or critical.
In short, the cloud isn’t just the future of data infrastructure — it’s the present engine of AI readiness. The research, also, notes a move to the cloud sees increased spending in both public and private clouds with AWS and Microsoft still the top two.
Deep learning is a type of machine learning that uses huge amounts of data and powerful computer programs to recognize patterns and do complex tasks automatically. It's called "deep" because it uses many layers of processing — data goes through these layers, and each one helps the system learn more about the information before making a final decision. Instead of being told exactly what to do like regular computer programs, deep learning systems learn from examples, getting better over time.
Without question, advances in hardware have slashed the cost and time required to power deep learning models, accelerating AI development. But the next leap forward will come from smarter models and better algorithms — not just faster chips. Today, deep learning powers everything from basic data analysis to advanced AI that can create content or make decisions. In the 2010s, deep learning helped AI make big leaps in understanding images, speech and language, setting the stage for what AI can do today.
Our research shows that successful AI systems need more than just deep learning. They also rely on tools like models that predict trends, ways to spot unusual data, explain why a model made a certain decision and methods to make smart choices with limited resources. It's also important that these tools are easy to use — features like drag-and-drop interfaces, quick testing options and the ability to use Python make a big difference.
Right now, the most important tools are ones that let AI work directly inside databases and use fast memory for better speed. There's also growing interest in features that let systems handle big jobs, run in the cloud, use graphics cards (GPUs) and combine different types of computing — showing that AI technology is becoming more powerful and flexible.
Related Article: How AI Is Reshaping Corporate Decision-Making — and What You Need to Know
Transformers are a major leap forward in deep learning. They’re designed to predict the next word in a sentence, which helps machines understand and generate human-like language. What makes transformers different from older models is that they don’t need labeled data to learn — they’re trained on huge amounts of real-world text and learn patterns directly from it. Transformers have become central to how we build AI systems today, alongside other popular approaches like artificial neural networks, convolutional neural networks (CNNs) and feed-forward models.
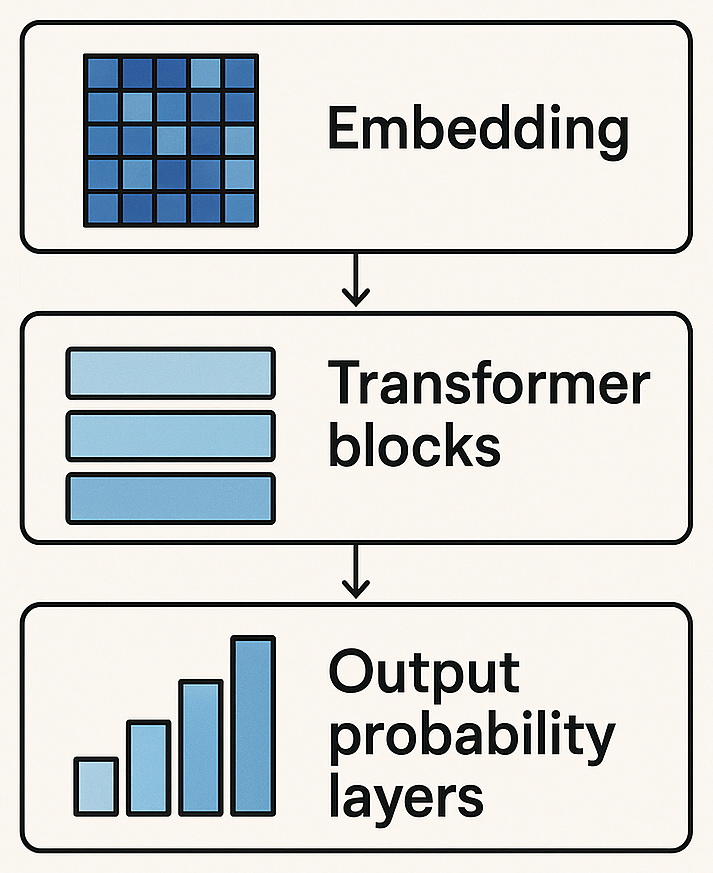
Every text-generative Transformer model — whether powering search, chat or content generation — relies on three foundational components: embedding, Transformer blocks and output probability layers.
Together, these elements enable models to understand and generate human-like language with remarkable accuracy and coherence.
The first step in the process is embedding. When text is input into a Transformer, it is divided into smaller elements called tokens, which may be entire words, subwords or even characters. These tokens are then converted into numerical vectors known as embeddings. These vectors are not arbitrary; they capture the semantic and syntactic properties of the input text, allowing the model to grasp nuanced meanings, contextual relevance,and even tone.
The embedded tokens are then passed through one or more Transformer blocks, which are the computational heart of the model. Each Transformer block consists of two major subcomponents: the attention mechanism and the multilayer perceptron (MLP). The attention mechanism allows each token to consider the importance of every other token in the sequence, enabling the model to build rich contextual understanding. For example, in the sentence “The bank approved the loan,” attention helps the model determine whether "bank" refers to a financial institution or a riverbank, based on the surrounding words. The MLP layer, meanwhile, refines the representation of each token individually. It applies nonlinear transformations to enhance the model’s ability to capture complex patterns.
Finally, the transformed representations are passed through a linear layer followed by a softmax function to produce output probabilities. These probabilities represent the likelihood of each possible token that could come next in the sequence. The model uses these probabilities to generate coherent and contextually appropriate responses, completing the cycle of text generation.
Large language models, like ChatGPT, are powerful versions of transformers built for generative AI. They use what they’ve learned from their training data to create new text, images or even code. These models understand words by looking at their context — basically, they figure out meaning based on how words are used together, a concept summed up by the phrase: “a word is known by the company it keeps.”
LLMs work by turning words into vector embeddings — mathematical representations in high-dimensional space. These embeddings store the meaning and relationships between words, helping the model grasp deeper ideas, not just isolated terms. Transformers then use grammar and sentence structure to add even more context and meaning.
These vector embeddings also help AI bridge the gap between how humans speak and how computers process information. Whether it’s text, images or audio, embedding models turn raw content into patterns of vectors, so that similar ideas are grouped together — making AI-generated content more accurate and human-like.
Vector databases are a key part of what makes large language models and other AI systems work so well. They store and organize vector embeddings — complex numerical representations of things like text, images or audio that capture their meaning. With these embeddings, vector databases can quickly find similar items across huge datasets, which powers applications like semantic search, chatbots, image recognition and recommendation engines.
Compared to traditional databases, modern vector databases are much faster — often 2 to 10 times better — because they’re built specifically for this type of data. They use smart algorithms, optimized storage layouts and a cloud-native design that lets different parts of the system (like search or indexing) scale separately. This makes them ideal for handling billions of vectors without slowing down, which is critical for large-scale AI systems.
Three main features make vector databases powerful:
Altogether, vector databases make it possible for AI systems to find and understand complex patterns in human-like ways, turning messy real-world data into useful insights.
In agentic AI, workflows are step-by-step sequences that intelligent AI agents follow to achieve specific goals with little to no human help. These workflows are built to be flexible, so the agents can adapt, make decisions and solve problems on their own in real time. By dividing big tasks into smaller ones, AI agents can handle complex work more efficiently and with less supervision.
As companies look to turn AI interest into real business results, one key approach is becoming clear: using AI agents. These autonomous agents are built to use business processes, often created for humans, to speed up business results and boost efficiency. Unlike traditional AI systems that need frequent human input, AI agents can manage and adapt workflows on their own as conditions change.
This shift allows businesses to get more out of their AI investments — automating repetitive or difficult tasks, improving decision-making and making processes more scalable. In short, AI agents are a major step forward. Instead of just supporting people, they’re starting to take the lead in driving business outcomes. To fully benefit from agentic AI, companies need to understand how these agents work and how their workflows operate by agents.
Related Article: AI Agents at Work: Inside Enterprise Deployments
The AI revolution is a story of powerful convergence — where foundational technologies come together to unlock unprecedented capabilities. From industrialized data and cloud computing to deep learning models, transformer architectures, vector databases and autonomous workflows, each enabler plays a distinct but interconnected role. Together, they form the backbone of analytical, generative and agentic AI, empowering organizations to move beyond experimentation toward scalable, sustainable impact.
Success hinges on mastering this ecosystem: making clean, accessible data available at scale; leveraging flexible, cloud-native infrastructure; harnessing advanced models that learn from raw data; efficiently managing semantic information; and automating complex workflows with intelligent agents. Those who invest strategically in these key enablers will not just participate in the AI revolution —they will lead it.
Don't miss Part 1, Part 2, Part 3 and Part 4 of our AI Revolution series.
 Learn how you can join our contributor community.
Learn how you can join our contributor community.
Myles Suer is an industry analyst, tech journalist and top CIO influencer (Leadtail). He is the emeritus leader of #CIOChat and a research director at Dresner Advisory Services. Connect with Myles Suer: 
