Feature
White Paper
Why Enterprise AI Fails at Scale

Think about it. Millions of tiny bots, crawling into every corner of the internet, to scrape it for information for artificial intelligence (AI) systems.
It’s enough to keep you up at night.
The problem is, those bots are keeping people up at night — in particular, IT people responsible for keeping their websites responsive under high traffic.
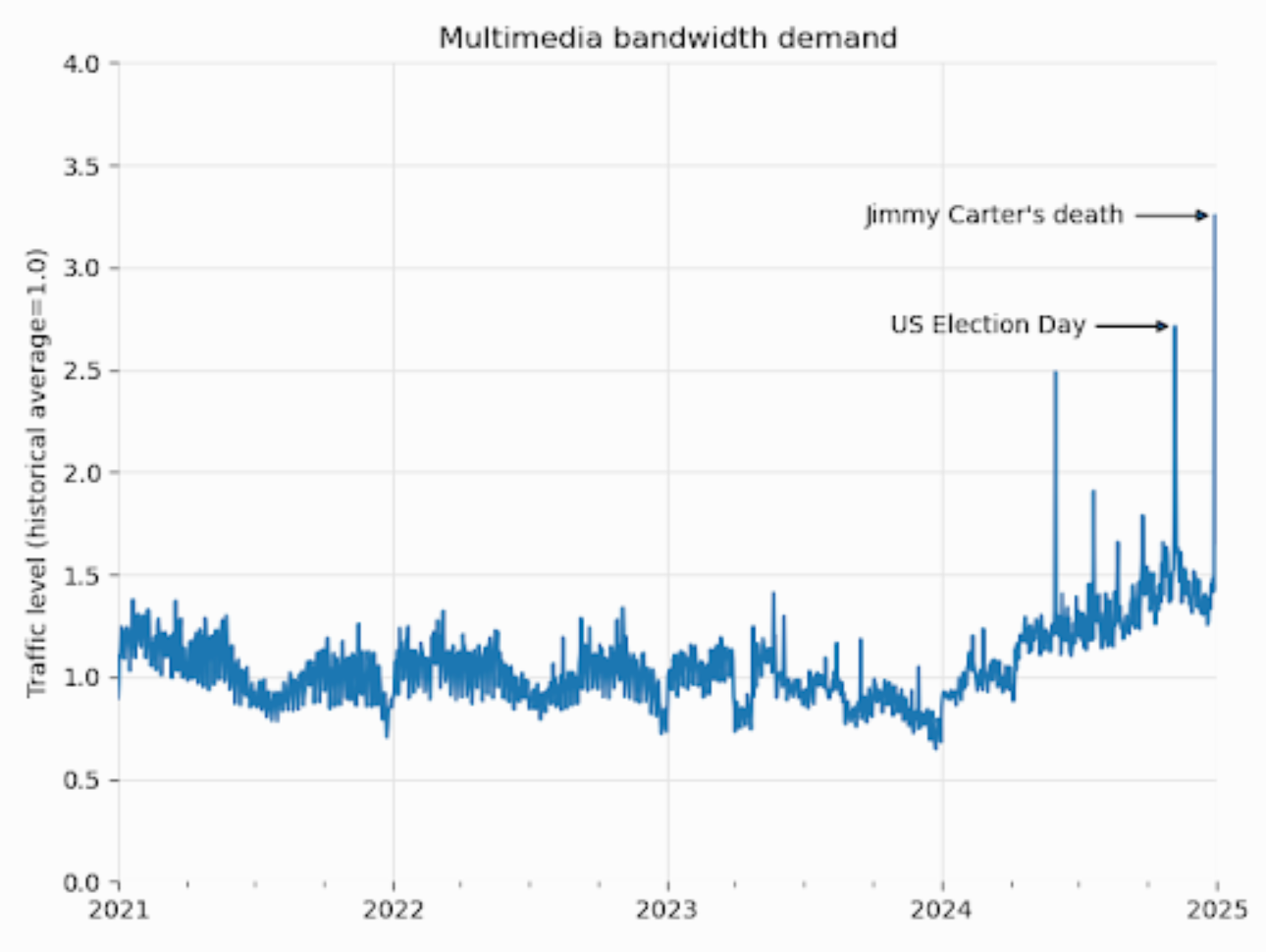
Since January 2024, the bandwidth used for downloading multimedia content grew by 50%, according to the Wikimedia Foundation. But this increase is not coming from human readers. It's largely from automated programs that scape its Wikimedia Commons image catalogue to feed AI models.
Other sites have reported similar problems.
Related Article: Inside Anthropic’s $1.5B Generative AI Copyright Lawsuit Settlement
The first internet scraper bot came around in 1993, just five years after the creation of the World Wide Web. The bot, named World Wide Web Wanderer, was built at MIT by Matthew Grey (current Google software engineer) to measure the size of the web.
Later, these bots were used for search engines, such as Google, according to David Belson, head of data insight at Cloudflare.
“Search platforms historically crawled web sites with the implicit promise that, as the sites showed up in the results for relevant searches, they would send traffic on to those sites — in turn leading to ad revenue for the publisher."
Even then, website operators had options. If they didn’t want bots indexing their websites, they created a robots.txt file using the Robot Exclusion Protocol that limited a bot’s access. That safeguard isn't as effective today.
The problem now is twofold.
First, more bots create more traffic as AI companies use them to learn information and create AI models. Software company TollBit reported a 9.4% decrease in human visitors to its sites between Q1 and Q2 in 2025. At the start of the year, 1 out of every 200 visitors to the site was AI. Now, it's 1 in every 50 — a 4x increase.
On top of the bot traffic, AI models fed by the bots aren't returning the favor. Previously, search engines sent traffic to websites that allowed bots as a means of repayment. That's happening less often with AI models. Instead, these models create AI-generated summaries so that people don't have to go to the original source of information.
Second, some AI bots are not following the rules.
“Not all crawlers respect robots.txt,” said Shayne Longpre, AI researcher and Data Provenance Initiative lead. “They don’t have a legal obligation to do so.”
Web administrators support this, reporting that they see AI systems with information that could have only come from their sites, despite having robots.txt files set up. Some may not even see indications of bot traffic, with bots like Perplexity found to be obscuring their crawling identity to circumvent website preferences.
Earlier this year, for example, Reddit sued Anthropic for scraping its data to use in LLM training, in violation of its robots.txt files — despite Anthropic's claims that it respects these bot blockers. In this case, which is still in remediation, Reddit argues the AI company breached Reddit's terms of service by scraping data without permission, as opposed to using a copyright claim. Second, Reddit claims it's protecting plans to sell its own data, as with its 2024 $60M licensing deal with Google.
With traditional tactics off the table, website administrators are trying other measures.
“We’re in the Napster-era of web scraping, and what the industry needs is a Spotify-like solution," said Toshit Panigrahi, CEO and co-founder of TollBit.
Others say more is needed. “While it's good to see innovation around this problem, we're most interested in solutions that can benefit all users and site operators, not just customers of any particular service provider," said Starchy Grant, principal systems administrator at the Electronic Frontier Foundation. "We would need to see standards widely adopted that broadly affect the whole ecosystem.
Another solution is systems to reduce the load of AI bots by having just one vendor scraping data, then licensing that data.
“We haven't heard from anyone taking steps toward exactly this kind of system, but there are some precedents,” Grant said. “The Internet Archive's Wayback Machine provides snapshots of web contents as a public good; when they scrape a web page one time, it becomes a useful artifact for both site operators and visitors.”
Other examples are Shodan, a search engine for hackers and security professionals, and RECAP, which gives users free access to federal court documents once a given document has been viewed by a first user.
Related Article: Anthropic Accused of Massive Data Theft in Reddit Lawsuit
The problem is AI vendors that look for ways to circumvent these solutions, such as by developing bots that act more like a person.
“There’s an arms race on both ends,” Longpre said. Basic crawlers are easy to detect, he explained. But more sophisticated bots, though more expensive, are also in use.
“Websites may also have an uphill battle ahead of them when it comes to getting badly behaved scrapers to either respect their signals or pay up instead of continuing an endless cat-and-mouse game of attempting to disguise their traffic,” said Grant.
The problem with these tactics is they risk damaging what made the internet such a great information source in the first place: its openness.
If every website becomes its own walled garden, where only members get access to its content, the internet goes back to what it was before the days of Alta Vista and Google Search, when you had to have an idea of where you could find information before you looked for it. The serendipity of stumbling across a website with photos of cats in sinks or discussions of costuming in period movies wouldn’t happen anymore.
Moreover, if all the reputable sites with trustworthy information get locked up, only unreliable sites will be available for people and AI systems alike, and we won’t be able to trust any information we get from the web — or, worse, we’ll trust information that isn’t true. That becomes even more of an issue as AI companies run out of LLM training data.
In fact, there’s been a conspiracy theory since 2016 called the “Dead Internet Theory,” saying that the web consisted entirely of bots talking to each other, with no real human content. With the huge rise in bot traffic, the Dead Internet Theory could become reality.
“A bad outcome is that the only people able to access the data are the ones sophisticated enough for really powerful crawlers and who have made a deal,” Longpre said. “The Web would only be available to those who could afford it. It shouldn’t be available just to the highest bidder.”
Sharon Fisher has written for magazines, newspapers and websites throughout the computer and business industry for more than 40 years and is also the author of "Riding the Internet Highway" as well as chapters in several other books. She holds a bachelor’s degree in computer science from Rensselaer Polytechnic Institute and a master’s degree in public administration from Boise State University. She has been a digital nomad since 2020 and lived in 18 countries so far. Connect with Sharon Fisher: 