Feature
White Paper
Why Enterprise AI Fails at Scale

As businesses grow more data-driven, understanding where data comes from, how it moves and how it changes is no longer optional — it’s essential, especially when it’s used in conjunction with AI. That’s where data lineage comes in.
Data lineage is the process of tracking data as it flows through various systems, offering visibility into its origin, movement, usage and changes. Whether you're ensuring regulatory compliance, debugging broken pipelines or building trust in AI models, data lineage provides the transparency and traceability needed to effectively manage modern data ecosystems.
Data lineage is a detailed record of where data comes from, how it moves through systems and how it changes along the way. At its core, it’s the metadata-driven map that traces a data asset’s journey — from its point of origin to its final use in things like reports, analytics, machine learning models or regulatory disclosures.
As Xavier de Boisredon, COO at Castor, explained it: “Data lineage is like a family tree but for data.”
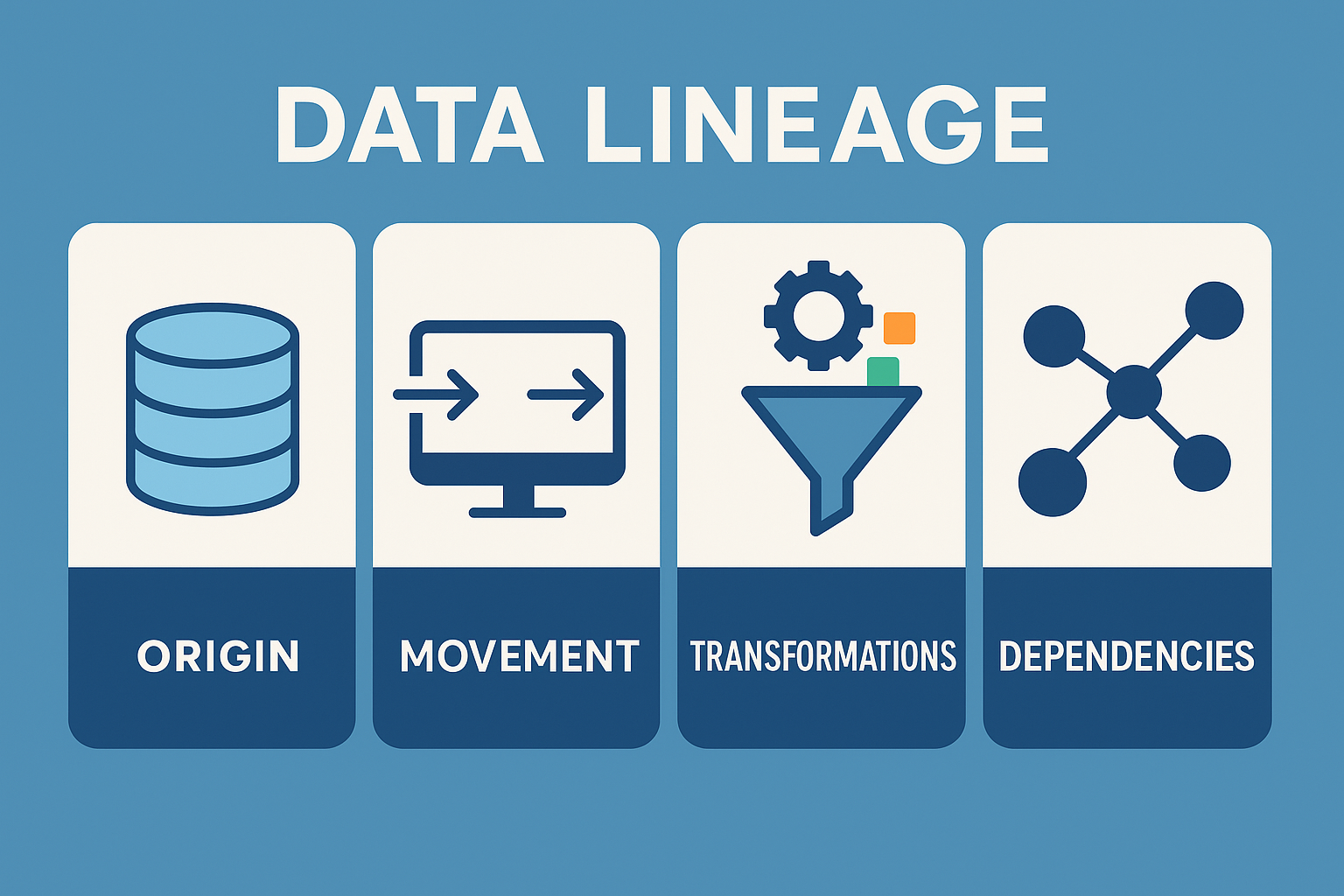
The data lineage process captures four key elements:
In modern data architectures, where data may pass through dozens of pipelines, applications and environments, lineage provides a crucial layer of data transparency — making data readily available, clearly interpretable and actionable for stakeholders — building greater trust.
Data lineage helps teams answer vital questions like:
Beyond debugging and quality control, data lineage plays a foundational role in compliance, governance and trust. It helps businesses comply with regulations such as the GDPR or HIPAA by showing who accessed what data, when and for what purpose. And as businesses increase their analytics and AI efforts, knowing the full context behind a dataset is essential to maintaining data integrity and accountability.
Related Article: How to Tell If Your Company Is Truly Data-Driven — and What to Do If It’s Not
Data lineage is a strategic necessity for businesses that depend on accurate, trustworthy data to make critical decisions. By tracking the origin, movement and transformation of data across systems, lineage enables transparency at every step of the data lifecycle.
This visibility supports a wide range of business and regulatory needs, including data quality assurance, operational efficiency, GDPR/CCPA compliance and AI model reliability.
| Use Case | How Data Lineage Helps |
|---|---|
| Debugging Data Pipelines | Quickly traces errors to root causes and reduces system downtime |
| Regulatory Compliance | Provides traceability to meet GDPR, HIPAA and CCPA audit requirements |
| Data Quality Assurance | Surfaces transformation history and helps validate trustworthy metrics |
| Responsible AI Development | Supports audit trails, bias tracing and explainability in model training |
| Executive Decision-Making | Provides transparency behind KPIs and reports to inform strategy |
One of the most common use cases is debugging broken data pipelines. When dashboards go dark or metrics suddenly drop, lineage helps teams quickly pinpoint where the issue occurred. Instead of combing through systems manually, data teams can trace the data flow in minutes, reducing downtime and improving responsiveness.
Data lineage also plays a central role in regulatory compliance. Regulations like GDPR, HIPAA, the EU AI Act, state AI laws and more require businesses to prove how personal data is collected, stored and used. Data lineage provides the traceability needed for internal audits or external regulators. When combined with role-based access controls and data classification, it becomes a powerful tool for enforcing data governance.
Data lineage improves overall data quality and trust. By surfacing the full history of a dataset — what it contains, where it came from, how it was altered — teams can validate its integrity before relying on it for reports or models.
This is particularly important in environments where multiple stakeholders touch the same data, such as in large enterprises or federated data teams. This decentralized model promotes agility and domain-specific ownership, while maintaining consistency through centralized standards and tools.
In regulated sectors like healthcare, understanding how data is collected, stored and used is crucial not only for compliance, but also for clinical integrity and risk mitigation.
Kyle Sobko, CEO at SonderCare, a business that regularly works with sensitive personal data, told us that data lineage gives his business some visibility on the flow of all its data (sometimes referred to as "data provenance"). "It establishes whether the information we leverage for care decisions is fit for purpose and it gives us the confidence there is a full history linked to the information with which we act."
Lineage is also foundational to responsible AI development. As AI governance matures, businesses need audit trails that show not just how a model was trained, but what data was used and why. Lineage helps identify potential sources of bias, ensures transparency in decision-making and provides the kind of documentation that regulatory frameworks will increasingly require.
“The conventional wisdom is that AI needs to be governed, and a significant element of that is understanding the data it is trained on and produces," said John Wills, founder and principle of Prentice Gate Advisors. "I agree 100%. Data lineage must play an essential role in the governing of AI."
Data lineage enhances analytics and business decision-making by giving context to the numbers. Instead of treating reports as static outputs, decision-makers can understand the assumptions, sources and logic behind the insights. This reduces reliance on guesswork, speeds up troubleshooting and builds organizational confidence in data-driven decisions. In addition, data lineage turns data from a black box into a clear, traceable asset — something that modern enterprises can trust, audit and act on.
More importantly, data lineage isn’t just a technical concern — it has financial implications. Without data integrity, AI tools risk failure, and decision-making suffers. Research shows that enterprises prioritizing structured information management realize measurable revenue advantages.
Swami Jayaraman, SVP and chief enterprise architect at Iron Mountain, said that data flaws can have broad implications and threaten the potential of AI tools — and even affect a company’s bottom line. J
“The companies that performed the best in our study were found to be much more likely to have data integrity checks and balances in place — especially in three critical areas: eliminating redundant, obsolete or trivial (ROT) data; automating data extraction; and encrypting data and installing security systems,” said Jayaraman.
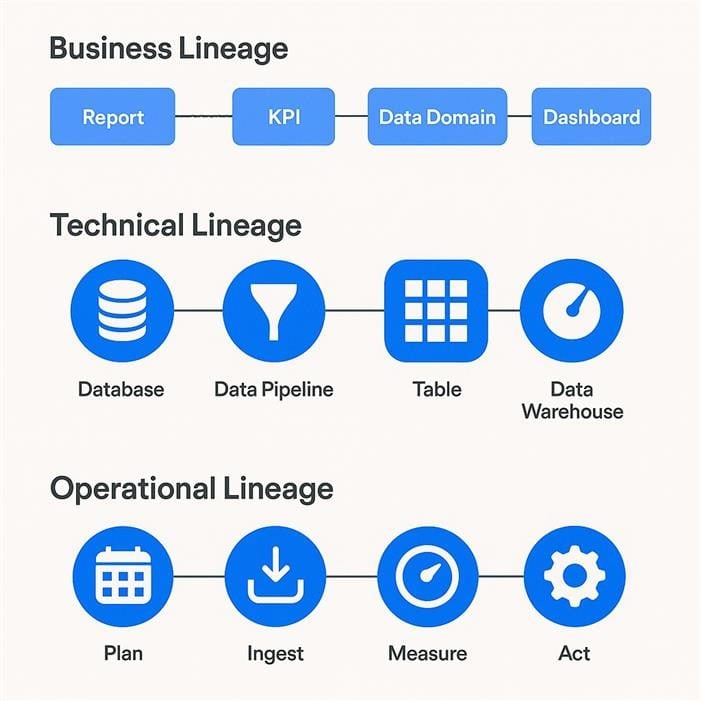
Data lineage can be documented and visualized at multiple levels of abstraction, depending on the audience and the use case. Broadly, it falls into three categories:
Each plays a distinct role in helping businesses understand and manage the flow of data.
| Lineage Type | Focus Area | Primary Users |
|---|---|---|
| Business Lineage | High-level view of data across departments and reports | Executives, auditors, compliance teams |
| Technical Lineage | Detailed trace of data through pipelines and transformations | Data engineers, architects, analysts |
| Operational Lineage | Real-time tracking of data movement for observability | SREs, DevOps, data operations teams |
Business lineage provides a high-level, stakeholder-friendly view of data movement across departments and systems. It focuses on the what and why of data, showing how a particular metric, report or business object is derived from upstream sources. This type of lineage is designed for non-technical users who need to understand where business-critical data comes from without getting lost in infrastructure details.
Technical lineage dives deeper into the how. It traces the exact flow of data through systems, tables, scripts and transformations, from source to destination. This version is often used by engineers and data scientists who need to track dependencies, validate data logic and understand system behavior. Technical lineage diagrams often include metadata flows, schema changes, ETL processes and versioning information.
Operational lineage offers a real-time or near-real-time view of how data moves through live systems. This type of lineage is invaluable for troubleshooting and monitoring, helping data teams identify failed pipelines, performance bottlenecks or unexpected anomalies as they happen. It answers questions like:
Operational lineage is typically embedded in observability platforms or monitoring dashboards.
Each of these lineage types plays a role in creating a complete picture of data flow. A well-integrated data governance program often combines all three, layering them based on stakeholder needs.
Related Article: Why Bad Data Is Blocking AI Success — and How to Fix ItAt its core, data lineage answers the question: Where did this data come from, and how did it get here? To do that, lineage tools rely on a combination of techniques, modes and pipelines.
| Data Lineage Technique | How It Works |
|---|---|
| Metadata Scanning | Extracts schema, table and column-level information from databases, warehouses and BI tools |
| Code Parsing | Analyzes SQL, Python or ETL scripts to map how data is transformed across workflows |
| Data Tagging | Adds unique identifiers to datasets, allowing their movement to be traced from origin to destination |
| Log Analysis | Uses logs from data platforms (e.g., Apache Spark, dbt, Airflow) to reconstruct the actual path data took through pipelines |
In addition, lineage tools typically operate in one of two modes:
Lineage is applied differently depending on whether data moves in batch or real-time:
Modern data lineage is rarely a standalone function. It’s increasingly built into broader data governance platforms and orchestration tools. These tools allow teams to visualize lineage alongside data quality metrics, usage patterns and access controls.
As data ecosystems grow more complex, purpose-built tools have emerged to automate and scale the tracking of lineage across environments. These platforms vary in approach, but all aim to provide visibility into how data moves, transforms and impacts downstream processes.
Open-Source and Developer-First Tools
Platform-Native Lineage Solutions
Enterprise Data Governance Platforms
Choosing the right lineage technology depends on the priorities of a business’s teams — whether that’s developer observability, audit readiness, business intelligence trust or regulatory compliance.
When evaluating lineage platforms, consider the following:
The most effective solutions often combine multiple tools, allowing businesses to personalize lineage capabilities to their architecture and maturity level.
Related Article: Making Self-Service Generative AI Data Safer
While the benefits of data lineage are clear, implementing it at scale is far from straightforward. Many businesses run into real-world challenges — both technical and organizational — that can hinder adoption and limit impact if not addressed early.
The nuances of implementing data lineage in complex architectures can be difficult, said Sobko. "Obviously on-premise and cloud with privacy issues is going to be more difficult than just cloud, etc."
When building visibility of data across all platforms at his company, Sobko said it took substantially more focused thinking to be consistent. "I noticed that combining data lineage processing capabilities with observability tools heightens governance and builds respectable confidence in AI / ML, etc.” Tools that create visual road-mapping of data flows — and update automatically — allowed them to manage their scaling and complexity.
Today’s data ecosystems are rarely centralized. Most enterprises operate across a mix of cloud platforms, on-prem systems, legacy databases and third-party SaaS tools. Capturing lineage across this fragmented stack requires integrating multiple sources, often with inconsistent metadata standards or access constraints. The result is that lineage maps are frequently incomplete or skewed toward specific systems.
Lineage depends on metadata, but not all systems generate it consistently or at the required level of granularity. In some cases, critical transformations occur in custom code or spreadsheets that fall outside traditional data pipelines. Without reliable metadata capture, lineage diagrams can become patchy or misleading, eroding trust in the system.
"In complex or hybrid environments, stitching together lineage from disparate, often proprietary systems (on-prem, multi-cloud, SaaS apps) becomes a manual, resource-intensive nightmare without a coherent strategy for unified metadata and integration," said Andrey Meshcheryakov Alexa, senior consultant at data strategy firm Recombinators.
Data lineage is a foundational element of trustworthy, compliant and scalable data operations. While implementation isn’t without challenges, the ability to trace data flows across complex systems is now critical for analytics, regulatory readiness and AI governance. Businesses that embed lineage into their data strategy today will be better equipped to manage risk and earn lasting trust in their data.
The terms are often used interchangeably, but there’s a difference: provenance focuses on the origin of data (where it was created and how it has evolved), while lineage traces the entire journey, including origin, movement, transformations and dependencies.
Provenance is a subset of lineage, not a replacement.
Not necessarily. Most lineage tools rely on metadata scanning, code parsing or log analysis, not AI. However, newer platforms are beginning to use AI to suggest missing lineage links and predict downstream impacts when something breaks.
Businesses use data lineage to:
It supports better reporting, reduces downtime, improves trust and aids responsible data governance across hybrid cloud environments.
Scott Clark is a seasoned journalist based in Columbus, Ohio, who has made a name for himself covering the ever-evolving landscape of customer experience, marketing and technology. He has over 20 years of experience covering Information Technology and 27 years as a web developer. His coverage ranges across customer experience, AI, social media marketing, voice of customer, diversity & inclusion and more. Scott is a strong advocate for customer experience and corporate responsibility, bringing together statistics, facts, and insights from leading thought leaders to provide informative and thought-provoking articles. Connect with Scott Clark: 