Feature
White Paper
Why Enterprise AI Fails at Scale

"What you can't measure, you can't manage."
The popular quote (often attributed to Peter Drucker, though likely apocryphal) accurately sums up researchers' current outlooks on artificial intelligence. They're seeking ways to measure AI performance so that different systems can be more easily compared and managed.
The big question: What should AI benchmarks measure?
Simply put, an AI benchmark is a way of measuring the performance of an AI system. There are many kinds of benchmarks and they depend on the type of AI system and how it’s used.
Three of the most common AI benchmarks are:
This benchmark suite encompasses both data center and edge systems and is designed to measure how quickly systems can run AI and machine learning models across a variety of workloads, according to AI engineering consortium MLCommons.
“The open-source and peer-reviewed benchmark suite creates a level playing field for competition that drives innovation, performance and energy efficiency for the entire industry,” the organization noted. “It also provides critical technical information for customers who are procuring and tuning AI systems.”
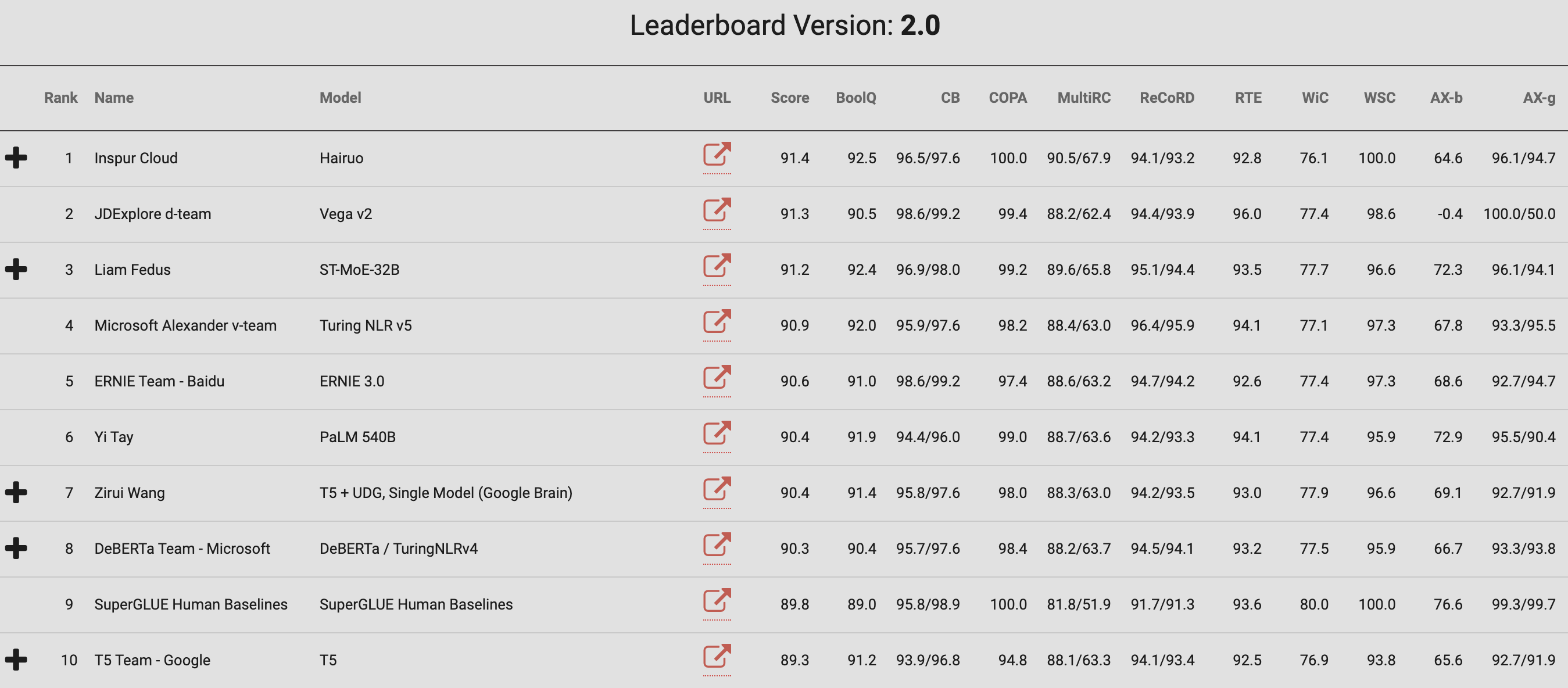
The General Language Understanding Evaluation (GLUE) benchmark is a collection of resources for training, evaluating and analyzing natural language understanding systems, according to the organization behind the metrics.
“The benchmark tasks are selected so as to favor models that share information across tasks using parameter sharing or other transfer learning techniques,” the organization said. “The ultimate goal of GLUE is to drive research in the development of general and robust natural language understanding systems.”
The organization has also released a new benchmark, SuperGLUE, incorporating lessons learned from the original. This benchmark includes a new set of more difficult language understanding tasks, improved resources and a new public leaderboard.
The Massive Multitask Language Understanding (MMLU) benchmark is designed to measure an AI model's multitasking accuracy. It includes 57 tasks, covering topics in social sciences, mathematics, humanities and more, ranging in difficulty from elementary level to advanced.
When this benchmark came out in 2020, the researchers behind it noted that most recent models had near random-chance accuracy — though the GPT-3 model improved over random change by almost 20%. Still, on every one of the 57 tasks, the best models still needed "substantial improvements" before they could reach expert-level accuracy.
All AI benchmarks are not alike. Researchers at Stanford noted that, of the 24 benchmarks evaluated, the MMLU benchmark scored the lowest in terms of usability. On the flip side, another commonly used benchmark, GPQA (Graduate-Level Google-Proof Q&A Benchmark), scored much higher.
The researchers noted that "it is common for developers to report results on both MMLU and GPQA without articulating their limitations or quality differences — for example, when introducing major models such as GPT-4, Claude-3 and Gemini. Similarly, the UK’s AI Safety Institute has developed a framework for evaluating LLMs that includes both MMLU and GPQA, while the EU AI Act specifically mentions the use of such benchmarks. This means policymakers and other actors often rely on conflicting and even misleading evaluations.”
Related Article: How to Evaluate and Select the Right AI Foundation Model for Your Business
It’s not unusual for enterprises to rely on benchmarks to determine the quality of a hardware or software product. However, according a comprehensive review of AI benchmark literature, benchmarks end up shaping AI much more than they do other computer products.
“Benchmarks are deeply political, performative and generative in the sense that they do not passively describe and measure how things are in the world, but actively take part in shaping it,” the authors noted. “This happens as benchmarks continuously influence how AI models are trained, fine-tuned and applied — practices with wide-ranging political, economic and cultural effects.”
Altogether, they found nine main categories of issues with benchmarks:
The authors also noted a variety of potential solutions, including:
“We especially identify a need for new ways of signaling what benchmarks to trust,” the review concluded. “We do not necessarily need standardized benchmark metrics and methods. But we do need standardized methods for assessing the trustworthiness of benchmarks from an applied and regulatory perspective.”
Ultimately, the authors identified a strong incentive gap in the use of certain benchmarks: researchers are interested in methods development and the "fast" logic of academic publication, corporations have economic interest and regulators consider practical utility and potential downstream effects.
Related Article: Why AI Data Centers Are Turning to Nuclear Power
Some are suggesting that different ways of benchmarking AI performance could be more helpful. For example, a typical person looking at automobile benchmarks might find “miles per gallon” as a more useful benchmark than 0-60 times.
Similarly, with the increasing focus on the amount and cost of electricity that AI systems require, there’s increasing interest in benchmarking AI models by the amount of energy they use.
One example is the AI Energy Score, announced by Salesforce, Hugging Face, Cohere and Carnegie Mellon University in February 2025. The goal of the project is to come up with a rating for AI systems similar to the Energy Star rating for household appliances, with a public leaderboard demonstrating results.
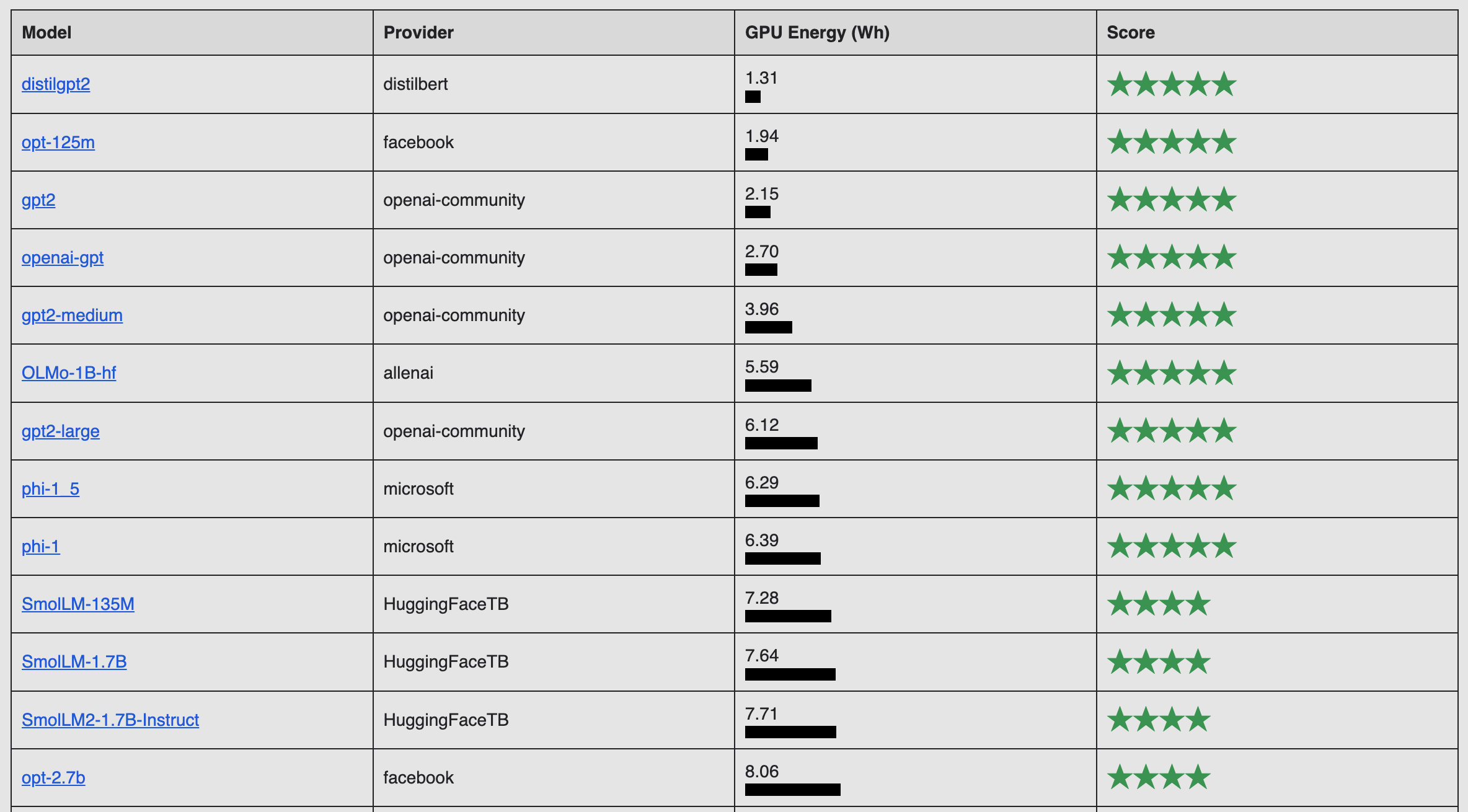
However, in the same way that energy-efficient cars don’t help if people really want to drive SUVs, it isn’t clear how helpful energy-efficiency AI benchmarks will be, said Alex de Vries, founder of Digiconomist and PhD candidate at Vrije Universiteit Amsterdam, who’s been studying this topic for the past decade.
“In AI, there’s a big relationship between the ultimate size of the models you’re using, their performance and the resources consumed,” de Vries said. “Generally, bigger is better. If you have a bigger model, it will perform better, but use more resources. With a smaller model, you will sacrifice performance. An efficiency benchmark is not going to be that helpful in dealing with this dynamic.”
In fact, even with an efficient model, de Vries predicted that people will continue adding more parameters and data to it so that it will perform better and compete better in the market — but in the process, make it less efficient. The only case where this dynamic might not happen is in smaller, less competitive markets where adding additional resources to the model might not improve it much, he explained.
De Vries also pointed out that major AI players such as Microsoft and Google seemed to be paying less attention to sustainability goals than they did before the recent explosion in AI.
Google's greenhouse gas emissions, for instance, rose by 48% between 2019 and 2023, reaching 14.3 million metric tons in 2023 — a surge primarily attributed to data centers supporting AI. “Microsoft is also reporting extremely terrible environmental performance," said de Vries, "and AI is the cause of that, but it’s not slowing them down. Whatever happens to sustainability is a future concern — they don’t care about it right now.”
Sharon Fisher has written for magazines, newspapers and websites throughout the computer and business industry for more than 40 years and is also the author of "Riding the Internet Highway" as well as chapters in several other books. She holds a bachelor’s degree in computer science from Rensselaer Polytechnic Institute and a master’s degree in public administration from Boise State University. She has been a digital nomad since 2020 and lived in 18 countries so far. Connect with Sharon Fisher: 