News
Guide
Is AI Making Your Organization More Productive or More Dependent?


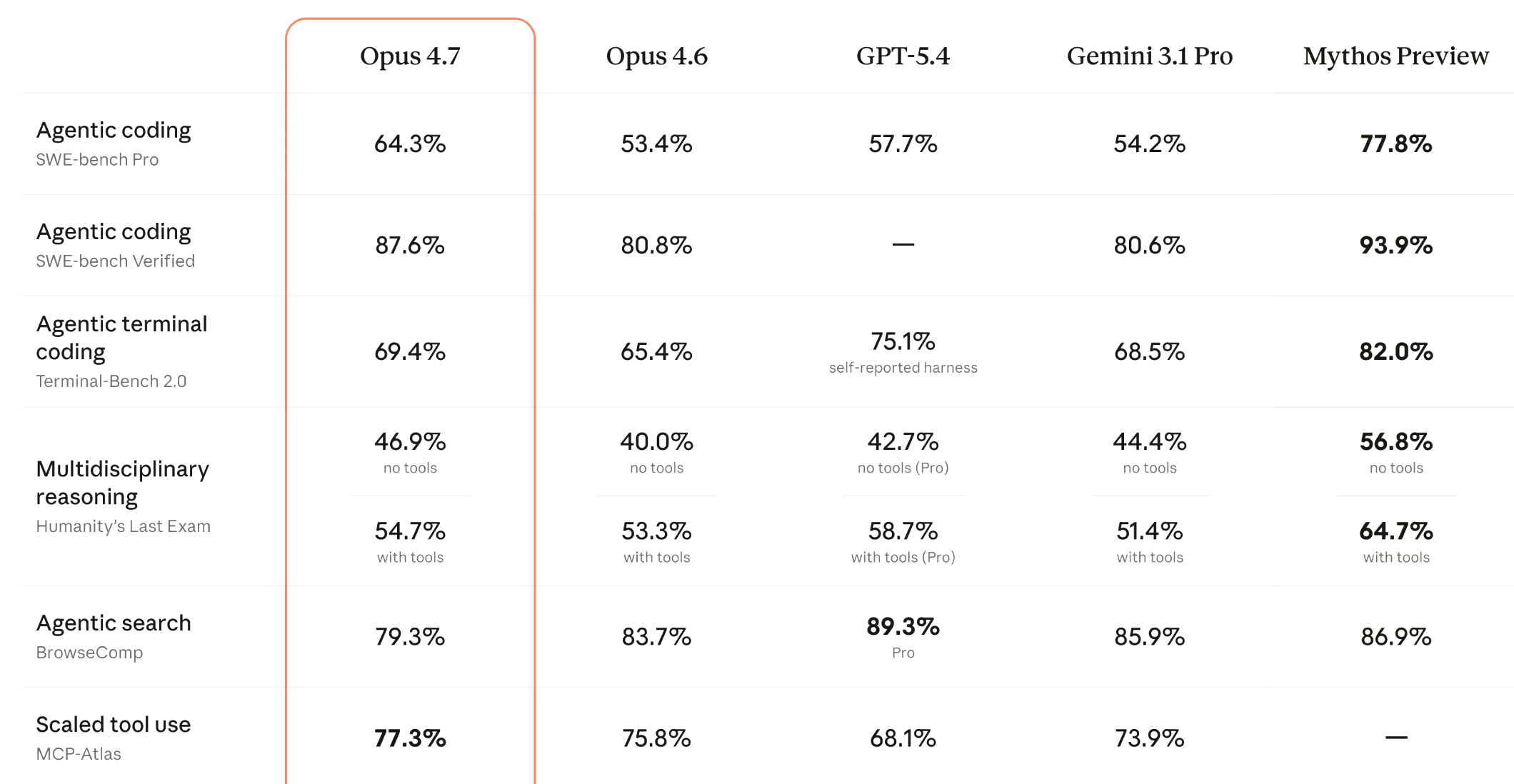
Anthropic has released Claude Opus 4.7, an upgrade to its flagship Opus model line that the company says delivers meaningful improvements in software engineering, visual understanding and long-running agentic tasks. The model debut also included a novel approach to managing AI's cybersecurity risks.
The biggest improvement with Opus 4.7 is in software engineering. According to Anthropic, users in early testing found they could delegate their most demanding, supervision-heavy coding tasks to the new model with confidence, something they couldn't reliably do with Opus 4.6.
That's a notable claim. Large language models (LLMs) have long struggled with what researchers call "long-horizon" tasks: multi-step jobs that require maintaining consistency and catching errors across many turns without human check-ins. Opus 4.7 reportedly does exactly that, with the model now verifying its own outputs before reporting results back to users.
The model also shows state-of-the-art performance on SWE-bench, a widely used software engineering benchmark, and tops leaderboard results on SWE-bench Multilingual and SWE-bench Multimodal variants.
Opus 4.7 accepts images up to 2,576 pixels on the long edge — roughly 3.75 megapixels — more than 3x the resolution supported by previous Claude models. That's a model-level change, meaning images are automatically processed at higher fidelity without any change to how developers send them.
The practical upside: use cases that depend on fine visual detail, like reading dense screenshots in computer-use agents or extracting data from complex diagrams, become substantially more viable.
Note: Higher-resolution images consume more tokens. Developers who don't need the extra detail can downsample images before sending them.
Anthropic describes Opus 4.7 as "substantially better" at following instructions. But the company flags an interesting side effect: prompts written for older models may now produce unexpected results, because earlier versions were prone to interpreting instructions loosely or skipping steps. Opus 4.7 takes instructions literally.
The company suggests that those migrating from Opus 4.6 or other older models should re-tune their prompts accordingly.
The model has improved ability to use file system-based memory, remembering important context across multi-session tasks. The result, according to Anthropic, is that later tasks in a long project require less up-front context-setting.
The most distinctive feature of this release may be a safety mechanism.
Last week, Anthropic announced Project Glasswing, a new initiative acknowledging the risks and potential benefits of powerful AI for cybersecurity. As part of that project, the company committed to keeping its most powerful model, Claude Mythos Preview, on a restricted release while testing new cyber safeguards on less capable models first.
Opus 4.7 is that test case.
The model includes automated systems that detect and block requests tied to prohibited or high-risk cybersecurity uses. Anthropic noted that during training, it also experimented with differentially reducing the model's cyber capabilities compared to Mythos Preview — an early example of targeted capability shaping, where developers try to make a model less capable in specific dangerous domains without degrading overall performance.
For legitimate security professionals — penetration testers, vulnerability researchers, red teamers — Anthropic is launching a Cyber Verification Program to grant access to capabilities that would otherwise be blocked.
| Detail | Info |
|---|---|
| Availability | All Claude products, API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry |
| API model string | claude-opus-4-7 |
| Pricing | $5/ million input tokens | $25/ million output tokens |
| Tokenizer | Updated — same input may use 1.0-1.35x more tokens than Opus 4.6 |
The token increase is worth planning for. Opus 4.7 uses an updated tokenizer and also thinks more at higher effort levels, particularly in later turns of agentic sessions. Anthropic says the net effect is favorable on its internal coding benchmarks, but recommends teams measure real-world token usage on their own workloads before fully migrating.
According to Anthropic, Opus 4.7 shows a broadly similar safety profile to Opus 4.6, with improvements on honesty and resistance to prompt injection, and modest weaknesses in harm-reduction advice around controlled substances. Claude Mythos Preview remains the company's best-aligned model by its own evaluations.