Editorial
Research Report
The AI Transformation 100: Concrete Ideas for Fixing How We Work


RAGAS testing on FinanceBench showed that common chunking strategies still struggle to balance precision, recall, faithfulness and relevance.
Your team finds a better embedding model. Switching costs three weeks of compute time, freezes analyst access and yields 2-3% in accuracy. So you don't switch. That is not a technology decision. It is a structural failure built into how most RAG systems are designed.
Most enterprise RAG systems carry the same liability, and it compounds the longer it goes unaddressed. The pipeline described here breaks the constraint by routing queries through semantic operators before search, indexing only the highest-information pages with selective fingerprinting and embedding only what each query needs at retrieval time. We validated the approach on the FinanceBench dataset using RAGAS.
| Full-corpus embedding is not a retrieval strategy. It is a technical debt that compounds with every document added, every model released, and every month you wait to move past it. |
|---|
Standard retrieval-augmented generation (RAG) breaks down documents into chunks, embeds those chunks and performs cosine similarity at query time. This approach is effective on a smaller scale. As you reach hundreds of thousands of vectors, the sheer volume of dimensions causes all similar vectors to be embedded in close proximity to each other; as a result, there becomes little to no difference in the geometric distance from relevant vs. non-relevant vectors. Researchers describe this phenomenon as semantic collapse; it is an inherent characteristic of the geometric structure of embeddings, not a matter of optimization.
The lock-in factor exacerbates this challenge. When a new model produces improved embeddings for the same document set that was previously used to train another model, the options are limited to either re-embedding every single document again or doing nothing.
Re-embedding a production corpus is a different matter entirely: every chunk — tens of millions of them across a large filing archive — has to be pushed back through the new model, the ANN index rebuilt from scratch and retrieval revalidated end-to-end. On shared or budget-limited GPU capacity, that runs into weeks of compute. During that timeframe, the retrieval tooling is unavailable.
Storage, indexing costs for ANN (Approximate Nearest Neighbor) indexes, GPU cycle costs to create embeddings and search compute costs also increase directly proportional to the corpus size. However, the quality of retrieval decreases inversely with the increase in corpus size.
Related Article: Taming GPU Burn: Cut GenAI Costs Without Slowing Delivery
The first modification is made before we do any searches.
A semantic operator exists between the user's query and the index. It takes every query and rewrites it based on the intended use of the query (financial information, legal requirements, etc.). The semantic operator identifies an intent for a query (i.e., financial performance or regulatory compliance), expands terminology associated with the query (a query regarding revenue growth may also include the terms "top line growth" and "sales performance") and limits where the query will be searched within the document (the Management Discussion Section as opposed to the entire 10-K).
The LOTUS Project from Stanford University and UC Berkeley found that a semantic operation, such as sem_filter, can process queries at speeds up to one thousand times faster than traditional methods, while increasing accuracy. Traditional RAG wastes most of its compute searching irrelevant documents; domain-aware routing eliminates those candidates before the costly vector comparison.
Instead of including every single page, this architecture generates lightweight semantic fingerprints for the most important pages of each document. Sparse distributed representation developed by Cortical.io encoded the words on a given page as a 128 x 128 binary vector, where each location contains an element of meaning. Bitwise comparisons, such as XOR and Hamming distance, run numerous orders of magnitude faster than cosine similarity over float vectors. The feature set is also interpretable — useful when reviewers need to know why two documents matched in regulated environments.
Financial documents follow a consistent structural format: executive summaries at the front of these types of documents, appendices at the back and substantive analysis in between. We generate fingerprints of the first and last pages of financial documents, along with coordinates of the high-density pages identified by LLM.
The resulting index covers about 7% to 10% of the pages found in financial documents. It also reduces embedding cost by about 80% to 90% compared to full-corpus indexing.
The cascading layers run at a very fast pace.
The semantic operator expands its intent quickly (in tens of milliseconds). Regardless of how large the corpus is, the fingerprint search returns candidate documents (annotated with page numbers) in milliseconds; there are typically five to fifteen candidates. For each candidate document, we perform an on-the-fly extraction that embeds only the relevant parts of that specific document. A cross-encoder then ranks the candidates based on their relevance, and the generation model generates the answer based on the ranked candidates.
The structural differences are summarized below. Efficiency follows directly from the design choices already described.
| Dimension | Traditional RAG | Hybrid Pipeline |
|---|---|---|
| Indexing scope | All pages, all documents | Key pages only (7–10%) |
| Comparison method | Cosine similarity (float vectors) | Bitwise operations (binary) |
| Hardware requirement | GPU for embedding and search | CPU sufficient for retrieval |
| Model dependency | Tied to one embedding model | Model-agnostic |
| Re-indexing on model switch | Full corpus (weeks) | Key pages only (days) |
| Index size per document | ~3 KB per 768-dim embedding | ~2 KB per 16,384-bit fingerprint |
Table 1. Architectural comparison of traditional full-embedding RAG and the hybrid fingerprint pipeline.
Many of today's RAG benchmark tests use surface level metrics such as BLEU (bilingual evaluation understudy) and ROUGE (recall-oriented understudy for gisting evaluation) to measure how similar two texts are based upon keywords rather than measuring the true quality of a retrieved document.
RAGAS (retrieval augmented generation assessment) breaks down the overall evaluation process into four possible types of failures in producing an acceptable response:
The breakdown allows for identifying the stage at which the multi-stage pipeline failed to produce an acceptable result, rather than simply indicating that the result was unacceptable.
Related Article: RAG vs. Fine-Tuning: A Practical Guide to LLM Customization
Four types of chunking have been tested for use on FinanceBench. FinanceBench was created by Patronus AI (an AI development company) and was first available in 2023.
The test evaluates how well large language models can be used to answer real-world financial question-asking. It includes a database of 10,231 questions that are based on open-book style information regarding publicly traded companies. Questions are paired with supporting evidence from SEC documents (such as the firms' 10-Ks, 10-Qs and quarterly earnings reports), where each document has both the supporting evidence text and the page number it appears on.
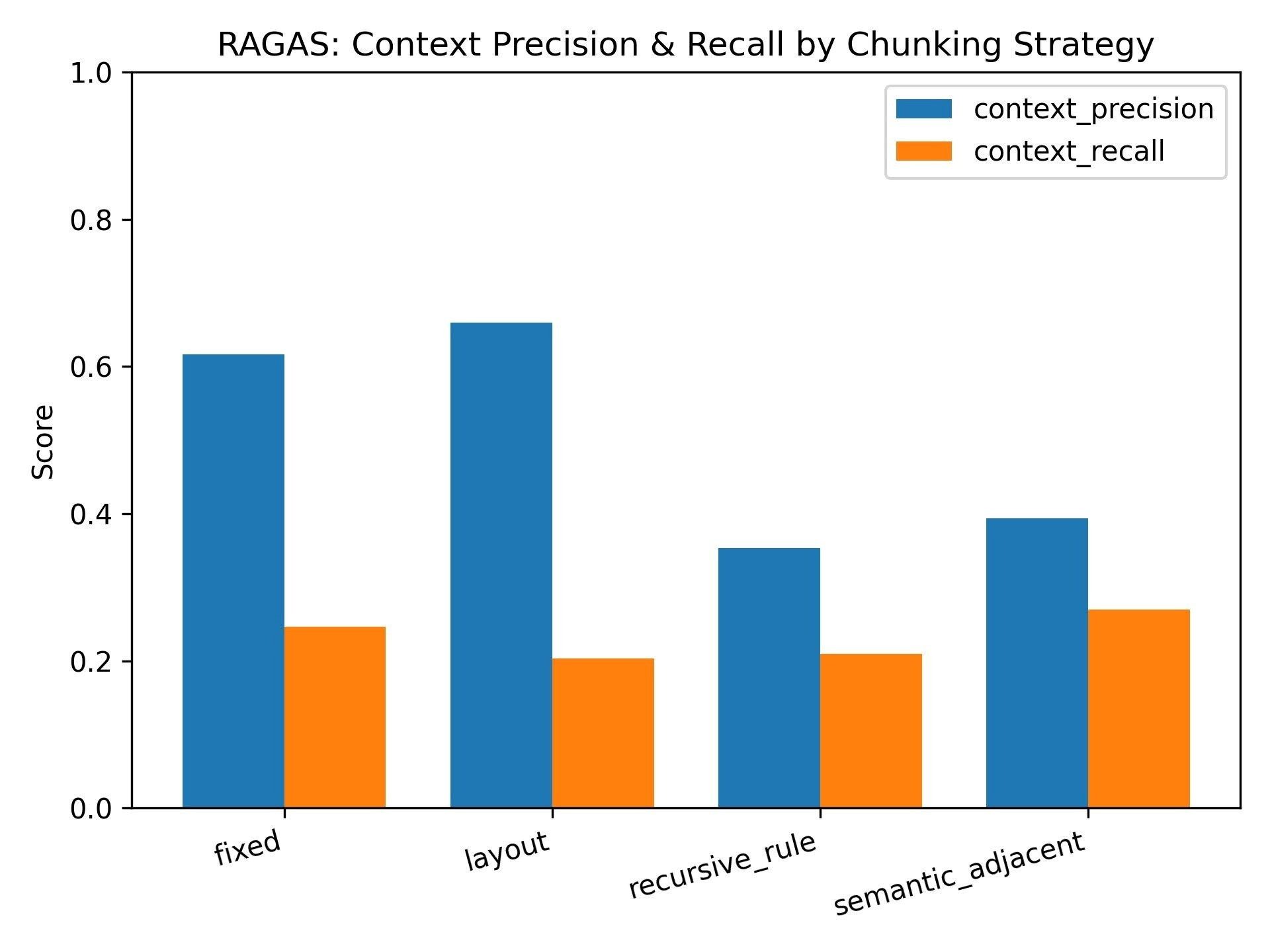
Although layout-based chunking resulted in a high level of precision (.66), it also had the lowest rate of recall (.203).
Fixed size was the second most precise method with an accuracy of .62 at a recall of .25 — missed approximately three quarters of all sections of multi-section documents.
The semantic-adjacent strategy produced the best results for recall, however its precision was limited to .39.
None of these strategies were able to resolve the issue that exists when trying to gather as much context from a document as possible while simultaneously reducing noise.
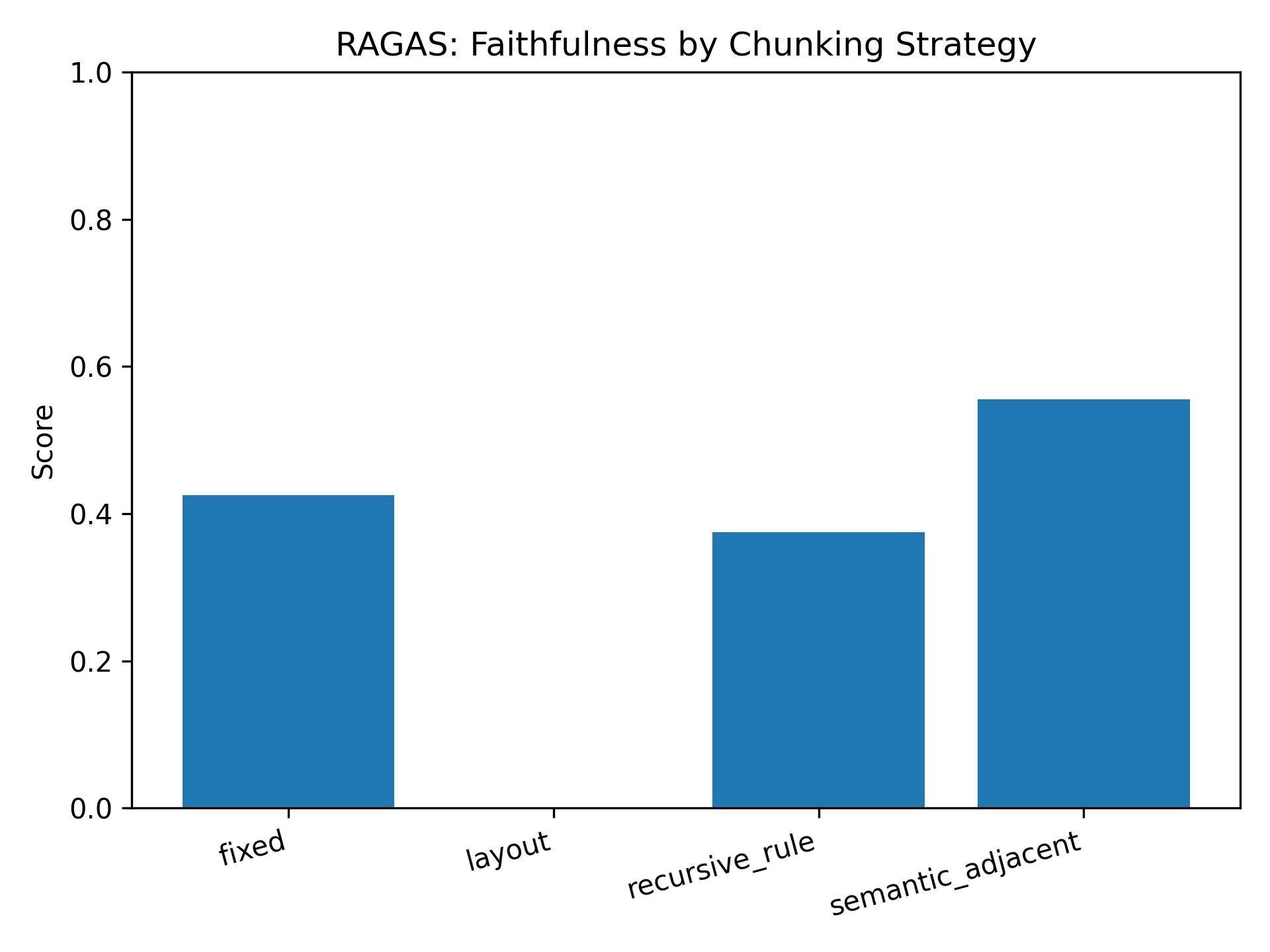
Faithfulness exposes a more dangerous failure.
Layout-based chunking scored 0.0 — the system retrieved relevant passages and then generated answers with no grounding in them. The pipeline appears functional while the LLM fabricates.
Semantic-adjacent led at 0.556 with the most grounded answers; fixed-size landed at 0.426.
In a financial compliance context, layout-based chunking's silent failure is the most dangerous mode available.
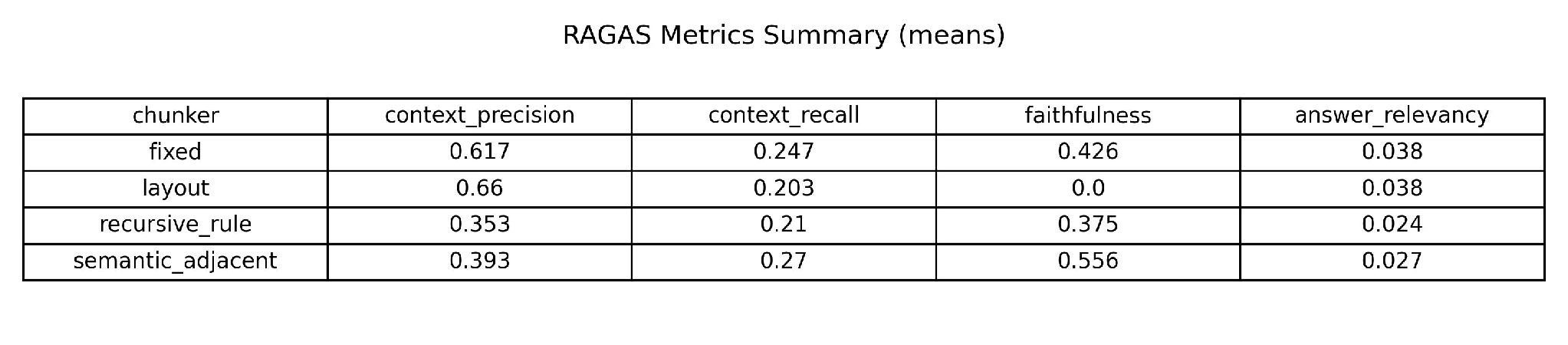
Reviewing these four metrics collectively (answer relevance) shows us what we were unable to discern when reviewing each metric individually; although answer relevancy ranged from 0.024 to 0.038 for every methodology used, no single "chunking" technique yielded an answer that consistently referenced the specific question being answered.
The ability to perform semantic fingerprinting is highly dependent upon domain-specific terminology. As a result, web-based training models will be able to process many of the higher frequency terms used within the finance industry; however, they will continue to have difficulty processing lower frequency terms (i.e., credit default swaps, mark-to-market valuation or exotic derivative structures).
One method for addressing this problem is to develop domain-specific models prior to deploying them into production. The second option would be to use model fine-tuning after it has been determined during the evaluation phase what aspects of these terms require additional support from the model.
Aggressive query rewriting can over-constrain searches.
We implemented two search processes in parallel: one where we rewrote the queries and one using the original queries. The results were then combined. All query rewrites are logged so that we may build a regression suite of known good transforms over time.
There needs to be a complementary layer to numeric and structural queries. For example, a query such as "list all companies that had revenues greater than $10 billion in 2024" cannot be answered by semantic fingerprinting alone. This type of query requires either some form of meta-data filtering or a post-retrieval verification process that addresses cases in which both the fingerprint and embedding pass fail to address.
Related Article: Are AI Models Running Out of Training Data?
The strategy of re-embedding isn't a solution; rather, it's an avoidance of what really needs fixing. Given that we're using the described system, testing a brand-new embedding model means re-fingerprinting a small subset of key pages — not re-embedding every one of tens of millions of chunks. Days — not Weeks. RAGAS illustrates for you exactly where the new model will improve your results and where it won’t.
You are no longer wondering if you should use anything other than full corpus based embeddings. Rather, you need to know how much time you have. Run RAGAS on your present process this week — and the difference in terms of precision vs. faithfulness will indicate which part of your existing system is currently failing. And then begin with a trial run on a select subset of document types prior to expanding.
 Learn how you can join our contributor community.
Learn how you can join our contributor community.
Himanshu Goel is an AI/ML Researcher focused on retrieval-augmented generation (RAG) systems for regulated enterprise domains, including finance, compliance, and biomedical workflows. He has judged Technovation and Devpost hackathons, served as a session evaluator and speaker at AiCon 2026 and PlatformCon 2026, and been a peer reviewer for FPA and AAIP 2026 conferences.