Editorial
Guide
Is AI Making Your Organization More Productive or More Dependent?


Every enterprise GenAI conversation eventually arrives at retrieval-augmented generation (RAG). The concept sounds straightforward: connect your large language model to your proprietary data so it answers questions about your business rather than generating responses from the internet’s general knowledge.
The appeal is real. But so is the gap between the concept and enterprise reality. RAG does not fix bad content. It amplifies it. If your content is disorganized, inconsistent or poorly structured, RAG will confidently serve up that disorder as legitimate answers. The AI does not know it is wrong. It sounds authoritative while delivering operationally useless results.
As Part 1 of this series established, the integration complexity of enterprise AI grows exponentially, not linearly. This article examines the foundational layer that manages that complexity: information architecture. There is no AI without IA.
RAG operates in three stages.
Most organizations focus their investment on stage three (generation) while underinvesting in stage two (retrieval).
The math is unforgiving. If your retrieval accuracy is 70%, meaning 30% of the time the system pulls the wrong documents, your overall accuracy ceiling is 70%. It does not matter how sophisticated your language model is. The system is working with wrong inputs, and no amount of generative sophistication compensates for retrieving the wrong source material.
HBR Analytic Services research found that 39% of organizations cite data issues as their top challenge in scaling GenAI, and more than half rated their data foundation readiness at five or lower on a 10-point scale. These are not technology problems. They are information architecture problems that surface as AI failures.
Related Article: No Agents Without Architecture: Why Enterprise AI Fails Before It Starts
Context is the most overused and least operationalized word in enterprise AI. Vendors invoke it to describe semantic understanding and vector embeddings. But context for enterprise retrieval is far more specific, and far more dependent on work that has nothing to do with AI technology.
Consider three questions that a field service technician might ask an AI assistant:
Each question sounds simple. Each is impossible to answer without context that must be built into the content architecture before the AI encounters it. The AI does not understand these distinctions. Your information architecture instructs it.
Here is a concept that transforms how you think about GenAI retrieval: every user prompt is a metadata container.
When a field service technician types, "I need to install a model 2960 modem, but I am receiving error code 50. Please provide the troubleshooting steps to complete my installation," they have embedded several metadata signals in the query:
The AI uses these signals to retrieve relevant content. But the AI can only find content that has been tagged with matching metadata. If troubleshooting guides are not tagged by product, model and error code, the system cannot match the query to the correct answer.
This is why organizations with excellent AI models still get poor results. The model understands what the user is asking. The content is not structured to provide the answer. The user’s question contains implicit metadata. The content must contain explicit metadata that matches. Information architecture builds the bridge.
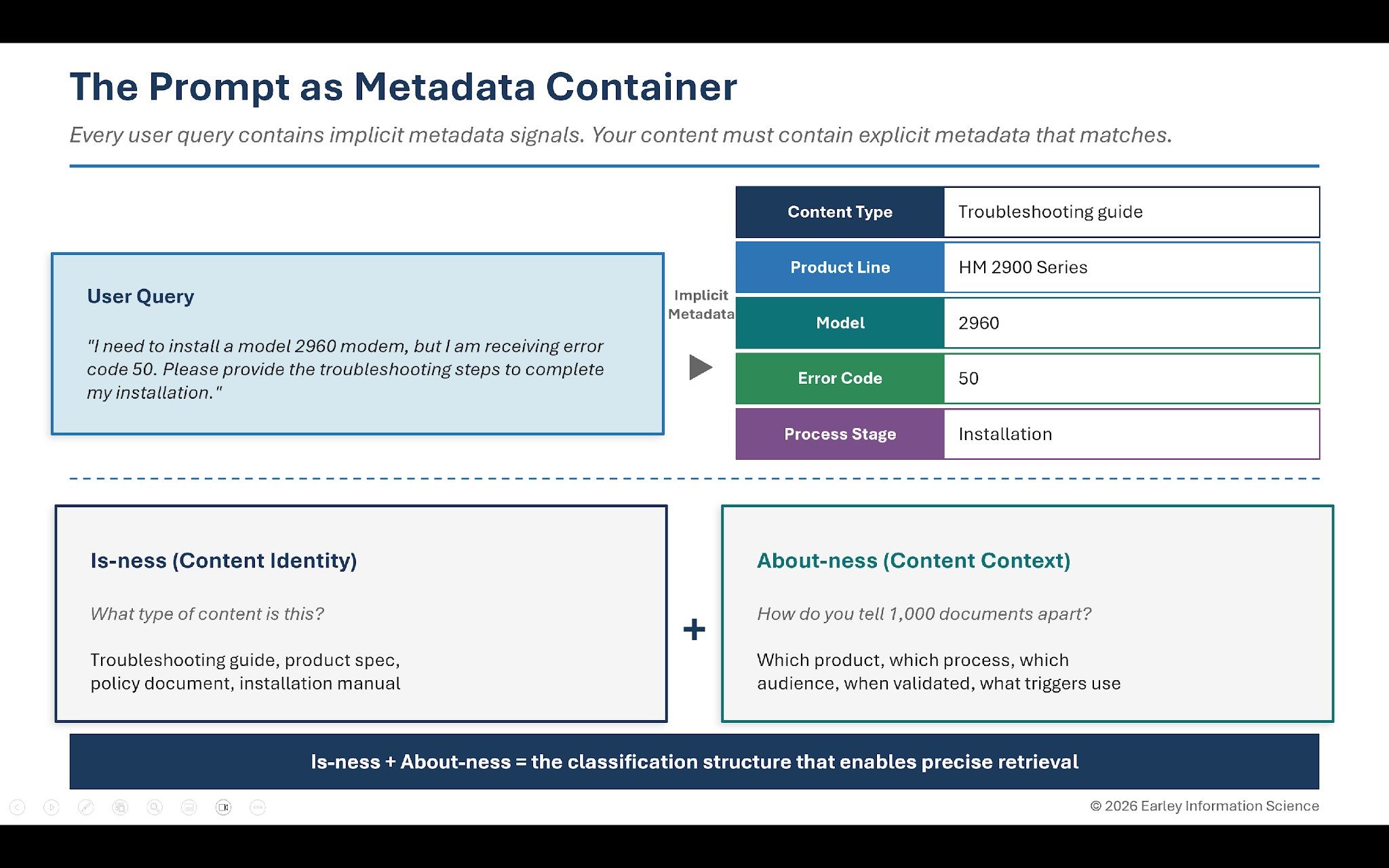
For over two decades, EIS has used a framework that provides the starting point for content architecture: is-ness and about-ness. Originally developed in the context of product data management and unified commerce, this framework applies directly to the enterprise AI challenge.
Is-ness answers: what type of content is this? If you handed it to someone, what would they call it? A service procedure. A product specification. A troubleshooting guide. A policy document. An installation manual.
About-ness answers: if you had a thousand documents of this type, how would you tell them apart? Which product does it cover? Which process does it support? Which audience is it for? When was it last validated? What conditions trigger its use?
Is-ness gives you content types. About-ness gives you the metadata schema for each type. Together, they create the classification structure that enables precise retrieval.
Most organizations have is-ness roughly figured out. They know a troubleshooting guide when they see one. Few have about-ness systematically defined. That is why their AI retrieves five troubleshooting guides when it should retrieve one.
Information architecture meets business strategy at the use case level. A simple formula defines the connection: "As a [role], I need to [action] so I can [outcome]."
For field service:
Each use case defines what metadata the content requires. The first tells you that troubleshooting guides must be findable by equipment type, symptom and error code. The second tells you that parts information must be linked to equipment, with availability status and procurement paths.
Multiply this process across dozens of use cases and you have identified your information architecture requirements, derived not from theoretical taxonomy exercises but from the actual work your AI needs to support.
This is also how you build test cases for RAG performance. Each use case becomes a question you can ask the system. If the AI cannot answer it accurately, you know exactly which content or metadata gap to fix.
Information architecture at enterprise scale sounds daunting. It does not have to be. The approach that works in practice is progressive enhancement, building metadata and structure incrementally rather than attempting comprehensive coverage from the start.
This sequence acknowledges organizational reality. Content owners have limited capacity. Governance processes take time to mature. Starting simple and iterating beats starting comprehensive and stalling.
Related Article: The Pilot Paradox: Why Enterprise AI Complexity Grows Exponentially
Organizations that build strong information architecture will not just have better GenAI. They will have built infrastructure that supports every future AI application: better search, personalization, analytics and eventually agent-based systems. The metadata foundation normalizes meaning across the enterprise, enabling integration between systems that were never designed to work together.
The AI landscape will continue to evolve rapidly. Models will improve and new capabilities will emerge. But the requirement for structured, well-architected content will remain constant. The organizations doing this work now are building a foundation that lagging competitors will struggle to replicate.
There is no AI without IA. The organizations that act on this will lead.
This is Part 2 of a three-part VKTR series on scaling enterprise AI. Part 1, "The Pilot Paradox," examined why the integration complexity of enterprise AI grows exponentially. Part 3, "Governance That Enables Iteration," addresses the feedback loops and operating model that sustain AI quality at scale.
 Learn how you can join our contributor community.
Learn how you can join our contributor community.