Editorial
Guide
Is AI Making Your Organization More Productive or More Dependent?


The pilot worked. The board approved expansion. And then the initiative stalled.
Across Fortune 1000 organizations, this pattern has become so common that it deserves a name: the Pilot Paradox. The very conditions that make a proof of concept succeed are the conditions that make enterprise deployment fail.
Research from Harvard Business Review Analytic Services confirms the pattern. When KPMG surveyed enterprise decision makers about barriers to GenAI implementation, the inability to access and leverage data ranked last among fourteen options, cited by only 16% of respondents. Yet once those same organizations tried to scale, 39% identified data issues as their top challenge. The obstacle was invisible until they hit it.
This article examines why the gap between pilot and production is not linear but exponential, and what that means for how organizations plan their AI investments.
Every successful proof of concept operates in conditions that exist nowhere else in the organization. A single, curated data source instead of fifteen contradictory systems. One department’s vocabulary instead of five competing terminologies. A data science team manually correcting errors that automated processes would need to handle across millions of queries. Clear success metrics defined by one stakeholder group rather than contested across ten.
The pilot succeeds because humans are quietly compensating for missing infrastructure. A data scientist spends forty hours cleaning a hundred documents. A subject matter expert catches wrong answers in weekly reviews. Everyone speaks the same language because they sit in the same department. None of that scales.
The prevailing guidance for technology implementation is to start small, get a quick win, then scale up. The problem is that scaling up is not a bigger version of the pilot. It is a structurally different problem.
Related Article: Your Science Fair Is Over. It's Time to Build the AI Factory
Most leaders assume scaling is proportional: if it works for fifty users, multiply resources to serve five thousand. This assumption treats each dimension of growth (departments, use cases, content sources, users) as independent. In practice, these dimensions interact multiplicatively.
Consider the individual dimensions first. A pilot typically involves one department, two use cases, two content sources and fifty users. An enterprise deployment might involve ten departments, twenty-five use cases, twenty content sources and five thousand users. Each dimension grows by roughly an order of magnitude.
If growth were additive, the enterprise deployment would require ten to a hundred times the resources. That is what most budgets assume. But the real complexity is not in the individual dimensions. It is in the connections between them.
Each department brings its own vocabulary, processes and priorities. Each content source has its own structure, metadata schema and update cycle. When these must work together in an enterprise AI system, complexity multiplies rather than adds.
Cross-department alignment (reconciling terminology, taxonomy and governance across groups) grows as n(n-1)/2. One department requires zero alignment challenges. Five departments require ten. Ten departments require forty-five. This is the combinatorial function that budgets ignore.
Content source mappings (schema reconciliation, deduplication, authority ranking) follow the same pattern. Two sources require one mapping. Twenty sources require up to 190 potential schema conflicts.
Use case and content source combinations (which sources serve which needs) multiply further. Even assuming only 40% relevance overlap, which is typical in enterprise environments, twenty-five use cases across twenty content sources produce roughly two hundred integration points.
Governance touchpoints (approval workflows, ownership boundaries, escalation paths) add another hundred or more.
The bottom line: a pilot with one department, two use cases and two content sources has roughly seven integration points to manage. An enterprise deployment with ten departments, twenty-five use cases and twenty content sources has five hundred or more. That is a seventy-fold increase in coordination complexity, before accounting for the hundred-fold increase in users.
The pilot succeeded because one team could hold all seven integration points in their heads. At enterprise scale, that institutional knowledge must be embedded in architecture, governance and process, or the system collapses under its own complexity.
This is why multiplying resources proportionally does not work. You cannot solve a combinatorial coordination problem by hiring more people. You solve it by building the infrastructure that makes coordination manageable: shared vocabularies, consistent metadata schemas, authority hierarchies and governance processes that span organizational boundaries.
The HBR Analytic Services research reveals why this blind spot persists. More than half of organizations surveyed rated their data foundation readiness at five or lower on a ten-point scale. Yet before attempting to scale, they did not view data quality as a significant barrier.
The explanation is structural. During the pilot, manual curation masks data quality problems. The team compensates without recognizing that compensation as a cost. When that compensation must scale, the cost becomes visible, but by then the organization has committed budget, set expectations and promised results based on pilot performance.
This is not a failure of due diligence. It is a failure of the mental model that treats enterprise AI as a linear extension of a successful proof of concept. The pilot and the enterprise deployment are different categories of problem, not different sizes of the same problem.
The organizations that navigate this transition share a common characteristic: they plan for integration complexity from the beginning, not after it emerges.
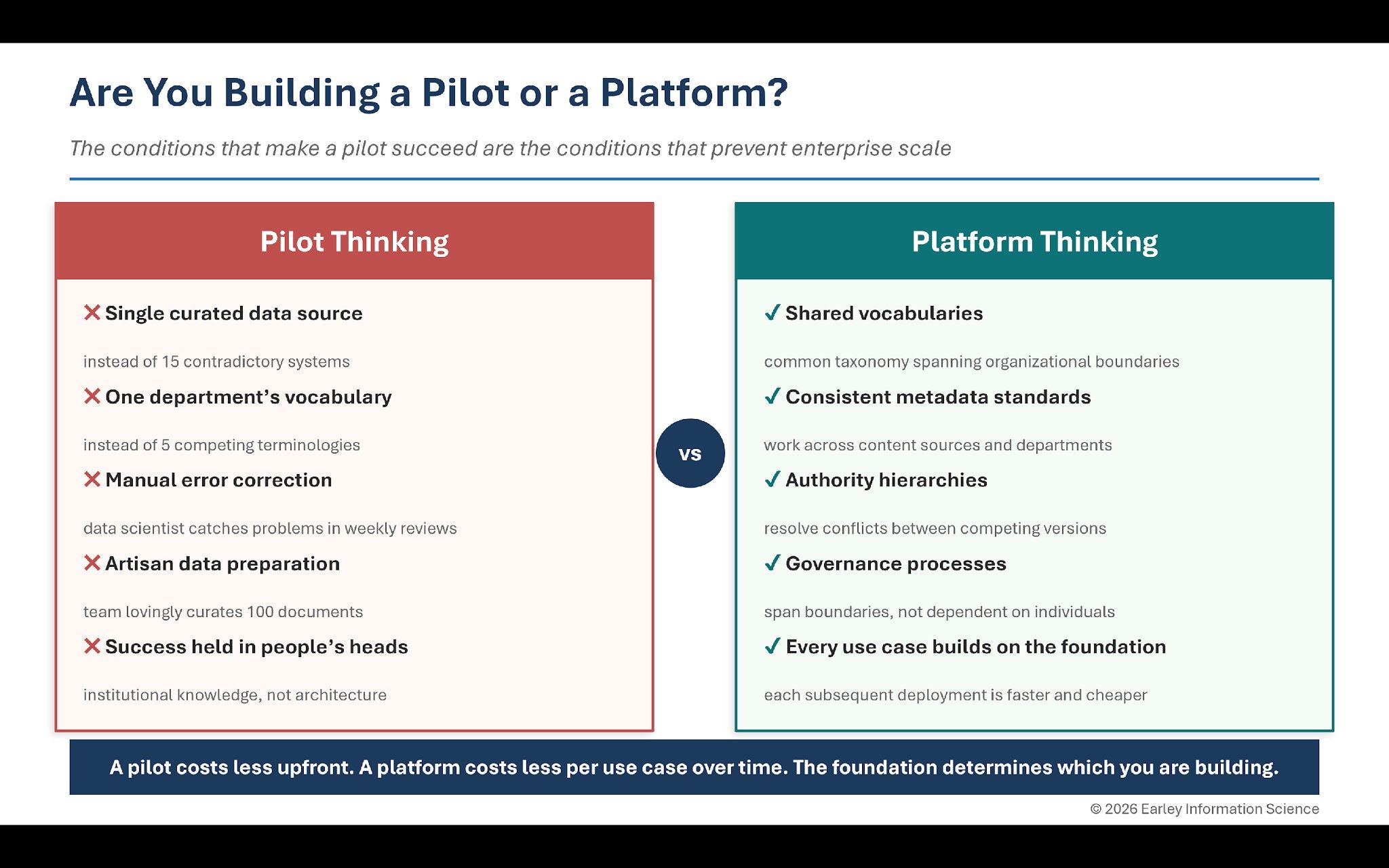
Before expanding beyond a single department, successful organizations invest in shared infrastructure: a common taxonomy that spans departmental boundaries, metadata standards that work across content sources and authority hierarchies that resolve conflicts between competing versions of the same information. This is the coordination layer that transforms a collection of departmental tools into an enterprise capability.
Every AI system will produce errors. The question is whether those errors get detected, diagnosed and corrected systematically, or whether they accumulate until users stop trusting the system. Organizations that scale successfully design their error-correction processes before deployment, not after the first crisis. (Part 3 of this series examines governance feedback loops in detail.)
The technology layer (models, embeddings, vector databases) evolves rapidly and costs decline over time. The content infrastructure layer (metadata, taxonomy, content models, authority structures) compounds in value. Every use case that builds on a shared content foundation is faster and cheaper than the first. Organizations that recognize this invest in the foundation as a platform rather than treating each AI project as an independent initiative. (Part 2 of this series addresses how information architecture provides this foundation.)
Related Article: The Semantic Layer + Data Virtualization: From BI Convenience to AI Necessity
The question most organizations ask is, "How do we scale our pilot?" The better question is, "Are we building a pilot or a platform?"
A pilot solves one problem in one department with manual curation. A platform builds the integration infrastructure that makes every subsequent use case faster, cheaper and more reliable. The pilot costs less upfront. The platform costs less per use case over time.
The integration math makes the economics clear. At seven integration points, manual coordination works. At five hundred, only architecture works.
The foundation you build today determines which answer applies to your organization tomorrow.
This is Part 1 of a three-part VKTR series on scaling enterprise AI. Part 2, "Garbage In, Confidence Out," addresses the information architecture foundation that enterprise retrieval requires. Part 3, "Governance That Enables Iteration," addresses the feedback loops and operating model that sustain AI quality at scale.
 Learn how you can join our contributor community.
Learn how you can join our contributor community.